The National League arguably entered 1880 in the best shape it had been in yet. Only one franchise had left the circuit; Syracuse was replaced by another small market, Worchester. The league’s top organized competitor (at least in terms of an alternative way to organize ball clubs), the International Association, had bitten the dust on September 29, 1879. On that same day, the league adopted a reserve clause that allowed each team to reserve five players each year.
The reserve clause was the brainchild of Bostons’s Arthur Soden, one of the three “triumvirs” who owned and operated the club. Soden had a reputation as a skinflint, and he was still smarting over the defections of Jim O’Rourke and George Wright to Providence. The rule did not draw much immediate outrage from players, who initially saw being reserved as a status symbol, but of course would become a matter of contention for nearly a century of baseball to come. Most teams used the reserve powers on their battery and three other players.
As usual, there were a fair number of on-field rule alterations. A foul ball fielded on the first bounce was once again an out after a year of using the modern rule. The number of balls needed for a walk was reduced to eight, and a third strike had to be caught on the fly for an automatic out. Additionally, the bottom of the ninth was no longer required to be played out if the home team had secured victory.
The pennant race was not much of one. The perpetually under achieving Chicago White Stockings blew the NL away, winning by fifteen games with a 67-17 record (good for an unsurpassed winning percentage of .798). Any doubt was removed in June, when Chicago caught fire--on July 8, they won their twenty-first consecutive game, improving their record to 35-3. Providence was next in line at 21-16, thirteen and a half games back. The two were essentially equal from that point; the White Stockings went 32-14 while the Grays went 31-16.
The dull season did include several impressive individual feats. On June 10, Charley Jones of Boston became the first player to hit two homers in the same inning. On June 12, John Richmond of Worcester pitched the first perfect game in major league history, a 1-0 triumph over Cleveland. Just six days later, perfect game #2 was turned in by Providence’s Monte Ward in a 5-0 win against Buffalo. On August 20, Buffalo got a 1-0 no-hitter from Pud Galvin against Worcester, and Larry Corcoran of Chicago handed the league’s newest member another no-no in a 5-0 game on September 20. Worcester and Buffalo thus both pulled the neat trick of pitching a no-hitter as well as being no-hit.
The off-season would yield some drama as Cincinnati was expelled from the league in an absurd morality play.
STANDINGS
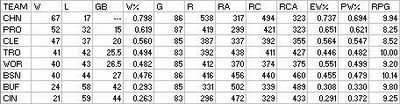
Chicago dominated the league in all three percentage categories, although their record W% was not matched in EW% or PW%. Troy managed to pull themselves up to respectability, while Buffalo went in the opposite direction. Boston fell out of the first division for the first time, and Cincinnati took the cellar in their swan song for the third time in the first five NL campaigns.
In 1880, the league hit .255/.271/.329, for a .094 SEC, 4.69 runs and 23.96 outs per game. The 4.69 runs was easily the lowest yet in the NL, as was the error rate (as seen in the .901 fielding average). Compared to 1876, R/G had dropped by 1.2 and the fielding average had improved by 35 points.
CHICAGO
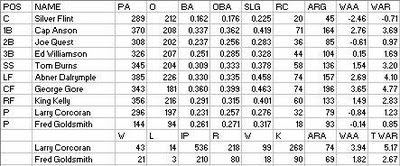
The White Stockings exploded on the league with improvement both at the plate and in the field, but it was the defense that made the big step forward. The regular lineup was largely intact (rookie Tom Burns took over shortstop, while King Kelly was pilfered from Cincinnati and took right field), so much of the credit would seemingly have to be given to the brilliant tandem of young pitchers the club unearthed. Twenty-one year old Larry Corcoran was a true rookie, while twenty-four year old Fred Goldsmith had worked 63 average innings (97 ARA) for Troy in 1879.
Offensively, Ed Williamson took a major step back in value while Silver Flint went from above average to below replacement level. This was offset, though, by a full season from a healthy Anson; replacing John Peters’ aging bat with Burns; and most of all, star-caliber seasons from Abner Dalrymple and second-year center fielder George Gore.
PROVIDENCE
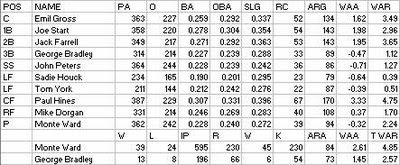
Providence tried Mike McGeary (shipped off to Cleveland after being removed) and Monte Ward at manager before turning the reigns over to Mike Dorgan (who served in that role for the Stars in 1879). Under Dorgan, the team went 26-12 and kept pace with Chicago; of course, they were already hopelessly buried along with the rest of the league.
The Grays did not have the services of Bobby Mathews this season (I’m not sure why, and some very perfunctory searching didn’t turn anything up), but they replaced him ably with Troy’s George Bradley. The reserve clause hit the team hard, though, as George Wright decided to retire to focus on his sporting good business rather than stay on (he appeared in one game for Boston before the Grays blocked further appearance on the basis of having reserved him); Jim O’Rourke was allowed to slip back to Boston, as he was not reserved.
John Peters brought his declining offense with him from the Windy City, while Jack Farrell was salvaged from Syracuse. Sadie Houck went to Cleveland mid-season.
The catching duties were turned over to Emil Gross, who had a promising rookie campaign in 1879 (a 167 ARG in 136 PA). He caught every inning of every game, and demonstrated that his offensive showing had been no fluke.
CLEVELAND
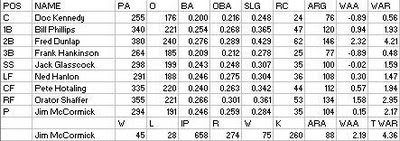
The Blues improved by twenty games largely due to the emergence of Jim McCormick as a very good (and iron; he pitched 63 innings more than anyone else in the league) pitcher, and rookie second baseman Fred Dunlap. Frank Hankinson and Orator Shaffer came over from the White Stockings while Pete Hotaling came from Cincinnati.
Rookie Ned Hanlon took over in the outfield after Al Hall, formerly with Troy, broke his league early in the season in Cincinnati. The Reds generously held a benefit on his behalf; Cleveland owner J. Ford Evans did not go, saying “I have to go to a champagne breakfast.” He then released Hall and left him stranded in the Queen City.
McCormick’s fine season was highlighted by his performance against the juggernaut White Stockings. No team (other than Cleveland) won more than three games from them the entire season. McCormick beat them four times himself. The most memorable was the July 10 game that snapped Chicago’s 21 game winning streak. Fred Dunlap cracked a two-run homer in the bottom of the ninth to give McCormick a 2-0 victory over Fred Goldsmith.
TROY
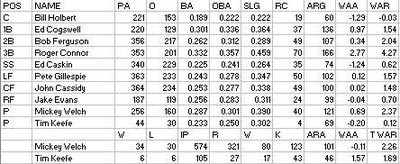
The Trojans overhauled half of their lineup, finding productive rookies in Roger Connor and Pete Gillespie, promoting John Cassidy and manager Bob Ferguson to regular roles, and bringing in Bill Holbert from Syracuse and Ed Cogswell from Boston (Cogswell took first base away from Dan Brouthers, who played in just three games). Their most fruitful move was replacing George Bradley as primary pitcher with a pair of outstanding rookies: 23 year old Tim Keefe and 20 year old Mickey Welch. Along with Chicago’s Fred Goldsmith, they made three outstanding rookie pitchers unearthed by the team.
The NL relented this season and allowed Troy to play their profitable exhibitions with neighboring Albany, but the rivalry almost cost the Trojans their spot in the league. Their May 15 game at Providence was rained out, and rescheduled for Monday the 17th (no Sunday ball in the pious NL, of course). Troy was scheduled to play Albany and chose to forfeit the league game so as not to miss the more profitable engagement. The Grays were furious and sought Troy’s expulsion, but the league decided that it was a “technical violation” since it was a make-up and not a regularly scheduled game. However, this was coupled with a strong warning not to do it again.
Boston and Providence had been so sure that Troy would get the boot that they had already started negotiating with Trojan players (the Reds with Caskin, the Grays with Cogswell, Holbert, and Welch).
Also of note is Keefe’s performance; I have him down for a 46 ARA, which is obviously great, but wouldn’t set any records. Baseball-Reference.com and other sources credit him with the best ERA+ in baseball history, 294. First, I’m not crazy about him being eligible as he only tossed 105 innings (the B-R criterion is one IP per team game; he qualifies, but pitching 105 innings in 83 team games while other pitchers in the league are pitching 500+ innings is not quite the same as 180 innings in 162 team games, as far as I’m concerned).
Secondly, Keefe allowed a large number of unearned runs, even for the time and place. He allowed 27 runs, only 10 of which were earned (37%). The team as a whole allowed 51% earned runs, while the league allowed 50% earned runs. It was certainly an impressive rookie season, but it was nowhere near being one of the greatest seasons of all-time.
WORCESTER
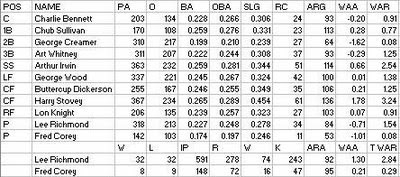
The Brown Stockings had to struggle to even gain entry to the National League, which had a rule that a city must have a population of 75,000 or else require unanimous approval from the other clubs. Troy opposed the Brown Stockings’ bid because they wanted to see their rival Albany admitted. To get around this, the league expanded territory to a four mile radius around the city, bringing Worcester up to the threshold.
The team used a variety of innovative techniques for financing, including: selling shares in the club (season tickets included) for $35, selling women-only season tickets, and holding a benefit walk that attracted 3,000 people.
The Brown Stockings lineup was comprised primarily of rookies and former NLers. Rookie pitcher Lee Richmond was a Brown University product who pitched one game for the Reds in 1879; he spent the winter working with backup catcher Doc Bushong (41 games). Fellow rookie Fred Corey had pitched five games for the Grays in ’79.
Rookies Harry Stovey and Arthur Irwin were the team’s top position players, while Art Whitney and George Wood were also rookie contributors. Charlie Bennett, the fine catcher, had last played for Milwaukee in 1878, and Chub Sullivan for Cincinnati in that year. The team was filled out by George Creamer of Syracuse and Buttercup Dickerson of Cincinnati.
In the campaign against the sinful Reds, one of the leading voices was the Worcester Spy. Unfortunately for the Brown Stockings, Cincinnati was in fact expelled and replaced by Detroit. The new franchise hired away the Brown Stockings’ manager, Frank Bancroft.
BOSTON
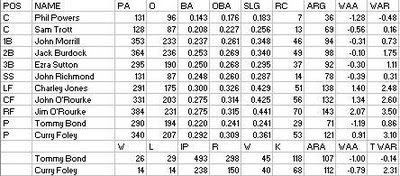
The Reds turned in what was easily the worst season in franchise history. The team had never before finished below a .557 W% or below third place, dating back to 1871. They also won NA/NL pennants in 1872-1875 and 1877-1878.
What was the cause? The team suffered WAR declines at every position except second base and right field (where Jim O’Rourke returned after a year in Providence). Phil Powers and Sam Trott, a pair of rookie catchers (Powers had played eight games for the White Stockings in 1878, while Trott was purchased from the independent Washington Nationals) did not match the production of Pop Snyder. Ed Cogswell was replaced at first base by John Morrill, which left a whole at third base. Ezra Sutton filled that spot, leaving a whole at short, where John Richmond, previously of Syracuse, did not play well. John O’Rourke had another fine season, but it was not as good as his rookie campaign.
However, the biggest problem was the collapse of Tommy Bond. Bond had totaled 12.4 WAR in his first three years in Boston and was the NL’s top pitcher in each of these seasons for my money. He fell to a 107 ARA; Curry Foley, the #2 pitcher, did not pitch any better than he had in 1879 (his ARA improved from 114 to 112), but he continued his fine hitting and contributed at first base and right field.
The decision to suspend and have one of their best players, Charley Jones, blacklisted did not help either. Soden ran the team along with two other men; they were collectively known as the Triumvirs and were considered very cheap. Supposedly they even collected the tickets at the gate themselves on occasion. Jones and Soden did battle when the outfielder asked for payment (reported as $378) while on a road trip. While the payday had technically come, it was customary for players to be paid when the team returned home. Soden decided to leave Jones behind in Cleveland and claimed he had jumped the club. Jones then took the matter to an Ohio court and got a ruling in his favor; this was enforced by taking a share of the receipts when the Reds played in Cleveland. Jones used this money to buy a laundry.
As an aside, a lot of these anecdotes may be apocryphal, to some extent or another. I am not a historian, and I have relied solely on secondary sources to gather them. So take them with a grain of salt, and please don’t get the impression that I’m trying to pass this off as a meticulous, 100% accurate history, or that I’m trying to pass myself off as a historian.
Case in point is how I have switched to using “Reds” as a nickname for Boston in this entry. Richard Hershberger pointed out in the comments that “Red Caps” was never used by primary sources, and he believes that the confusion stems from a St. Paul club listed as the Red Caps, which has bled over into the Boston NL franchise because of some writer’s misunderstanding. He suggested using “Bostons”, as this was the most commonly applied name, more so than even “Boston”. I did not go that far, but I do not want to contribute any further to the proliferation of Red Caps.
As long as somebody, somewhere referred to the team by a given nickname, that’s enough for me. I treat it as if I was writing about contemporary baseball, in which case I might refer to the “Bronx Bombers”, “the Tribe”, “the White Elephants”, “the Buccos”, etc. Using those nicknames in those veins is in no way a claim that they are official, team-approved, used extensively in press coverage, etc. It is in that same spirit that I used nicknames for the nineteenth century clubs.
BUFFALO
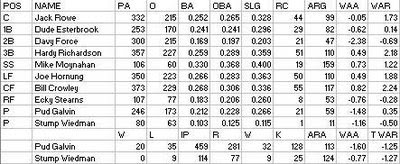
The Bisons collapsed from third place to seventh place and a sub-.300 W%. It didn’t help that Pud Galvin’s innings declined from 593 to 459, with his effectiveness also taking a serious hit (95 ARA to 113); he also held out in San Francisco very early in the season. Rookie #2 pitcher Stump Wiedman, just nineteen, was bad in the box and atrocious at the plate. Oscar Walker, decent at first base in 1879, was fined $50 in early June for breaking a temperance pledge and fell out of favor, playing in just 34 games.
Chuck Fulmer, my choice for all-star second baseman in 1879, played in just eleven games. The team also lost catcher and manager John Clapp. Rookie catcher Jack Rowe was solid, and rookie shortstop Mike Moynahan was very good in limited time (106 PA), but fellow rookies Dude Esterbrook and Ecky Stearns combined for sub-replacement level performance.
CINCINNATI
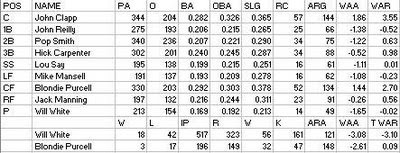
This Reds club was not the same one that competed in the NL in 1879. Instead, an independent team called the Stars was drafted to replace them. Thus, these new Reds did not have many carryovers from the decent 1879 club. The White brothers were the only returnees amongst the regulars, and Deacon missed much of the first half tending to his ailing wife, playing right field when he returned. Will suffered through a terrible season (-3.1 WAR). John Clapp was brought in from Buffalo to manage and catch; Hick Carpenter, Mike Mansell, and Blondie Purcell were all salvaged from Syracuse; and Jack Manning had last played with the Reds in 1878. Rookies Long John Reilly, Pop Smith, and Lou Say contributed little.
Any disappointment Reilly may have had over a replacement-level rookie season was probably offset by sheer joy of being alive. According to his SABR BioProject entry (written by David Ball, whose “Nineteenth Century Transactions Register” has also been a valuable source), Reilly and the Reds played in Providence on June 10, then had a couple of off days. So he went to New York City on a Long Island Sound steamer. On the June 11 return voyage, his boat, the Narragansett collided with another boat, the Stonington.
Reilly helped in various rescue efforts on board, then jumped into the water when it seemed the ship would sink and floated for around an hour while holding to piece of wood before being rescued. The Reds and Grays played again the next day, unsure of whether Reilly was dead or alive at first. He returned to the lineup on the 15th.
While errors were still quite common, the Reds’ August 28 game against Troy was a little excessive: nine errors in the fourth inning and sixteen in the game, which they lost 13-2.
The Reds as a major league franchise would not share the same joy of being alive as their first baseman once the season was over. The team insisted on renting its park out to non-league clubs that sold alcohol and played on Sundays. This led to calls for punishment against the sinners, with the aforementioned Worcester Spy a major player. A Cincinnati backer fired back against the critics, “Puritanical Worcester is not liberal Cincinnati by a jugful. We drink beer…as freely as you used to drink milk” (Seymour, pg. 92). Additionally, Cincinnati refused to accept Worcester’s chosen umpire, Foghorn Bradley, in retaliation (at this time, umpires were chosen by and would travel with the visitors).
On October 6, the NL voted unofficially to ban alcohol sales and Sunday ball on team grounds, 7-1. Cincinnati refused to sign a pledge to obey the rule, and was then expelled for not promising to vote yes when the matter came up for a formal vote.
(The league leaders and my "all-star" picks will be a seperate post, as Blogger will not allow to write anything past this point without double spaces. Why? I don't have a clue, and I'm not going to learn HTML to divine it. Also notice the single spaces after periods, which were double spaces in my Word document.)















