This post is going to lay out the math necessary to apply the so-called "Willie Davis method" of Bill James to his Runs Created and to Base Runs. The last three posts have explained how you can use it with Linear Weights. This is offered in the interest of comprehensiveness, should you decide that you’d like to fiddle with this stuff yourself.
The Willie Davis method as explained by Bill James is based on the most basic RC formula, (H + W)*TB/(AB + W). You could use one of the technical RC versions too, of course, but then you would introduce the problem of what to do with all of the ancillary categories that are included in those versions. A minor modification that would help matters is to give a weight to walks in the B factor (which is simply TB in the basic version), but James has never done that as it would complicate the basic version and mess up all of the neat little RC properties like OBA*SLG*AB = runs.
While I tried to emphasize that I wouldn’t take any of the results from the linear weight translations too seriously, the output of the Willie Davis method is actually used by Sean Forman to calculate OPS+ at baseball-reference.com. So while James used it in the vein that I advocate, Forman uses it to park-adjust the most-looked at total offensive statistic at his site. For this reason, I’ll compare park-adjusted OPS+ figured by his method to what I would do later in the post.
To apply the Willie Davis method to RC, first define a = 1 + W/H, b = TB/H, and outs as AB-H. You also need to calculate New RC, which I will abbreviate as N. That is just regular RC times the adjustment factor you are using (in a park case, if the PF is 1.05 then N is RC*1.05). Then this relationship holds:
N = (a*H)*(b*H)/(a*H + Outs)
This can be manipulated into a quadratic equation:
abH^2 - NaH - N*Outs = 0
And then we can use the quadratic equation to solve for H, which we’ll call H’:
H' = (Na + sqrt((Na)^2 + 4ab(N*Outs)))/(2ab)
The adjustment factor for all of the basic components (S, D, T, HR, W with outs staying fixed) is simply H'/H. So we multiply the positive events by H'/H and the result is a translated batting line.
Since we have applied this type of approach to RC and LW, we might as well do it for Base Runs as well. Allow me to start with this particular BsR equation, published some time ago by David Smyth:
A = S + D + T + W
B = .78S + 2.34D + 3.9T + 2.34HR + .039W
C = AB - H = outs
D = HR
BsR is of course A*B/(B + C) + D, and New BsR (N) is BsR*adjustment factor. To write everything in terms of singles, let’s define a, b, and c (of course, I didn’t realize until after I wrote this that a, b, and c are terrible abbreviations in this case, but I already had them in my spreadsheet and it would have been a real pain to change everything):
a = (S + D + T + W)/S
b = (.78S + 2.34D + 3.9T + 2.34HR + .039W)/S
c = HR/S
Then we need to solve for S' (the new number of singles) in this equation:
aS'*bS'/(bS' + Outs) + cS' = N
This results in a quadratic equation just as the RC approach does, and it can be solved:
S' = (Nb - cOuts + sqrt((cOuts - Nb)^2 + 4(NOuts)(ab + bc)))/(2*(ab + bc))
S'/S is then the multiplier for all of the positive events.
So we have three different approaches based on three different run estimators to accomplish the same task. Which one should be used? Unfortunately, there’s no good empirical way to test these approaches; the entire point of having them is to make estimates of equivalent value under different conditions…i.e. conditions that did not occur in reality.
However, I think it should be self-evident that the quality of the model from which the estimate is derived says a lot about its value. I don’t need to beat that horse again, but it is well-known that Basic RC is not a very good estimator when applied to individuals, which is exactly what we are doing here.
It would also follow that the Linear Weights-based approach should be marginally better than the Base Runs-based approach since BsR should not be applied directly to individuals. Since BsR is better constructed than RC, though, the discrepancies shouldn’t be as bothersome.
I am going to use the three approaches to derive park-adjusted BA, OBA, and SLG for the 1995 Rockies. In all of the calculations, I am using a 1.23 park factor for Coors Field. The unshaded columns are the players’ raw, unadjusted numbers; the pink columns are adjusted by the RC approach, orange by the ERP approach, and yellow by the BsR approach:
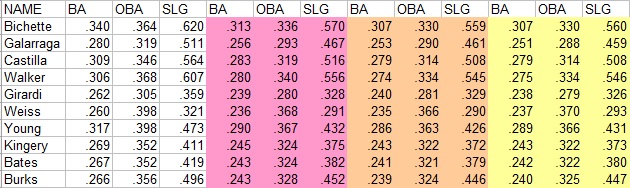
From eyeballing the numbers, I’d say that there is a strong degree of agreement between the ERP and BsR estimates, with the RC estimates as the outliers. As mentioned above, this is along the lines of what I would have expected to see, as both ERP and BsR are better models of the run scoring process than RC. That the ERP and BsR results are close should not come as a surprise, as both estimators give similar weight to each event.
Using RC results in a less severe park adjustment for most players. Why is this? My guess is that it is because RC, with it’s well-known flaw of overvaluing high-end performance, naturally needs to draw down the player’s OBA and SLG less then ERP or BsR to still maintain a high performance. In other words, RC overestimates Larry Walker’s run contribution to begin with, and since the problem only gets worse as OBA and SLG increase, it doesn’t take that that big of a change in OBA or SLG to reduce run value by X%.
As I mentioned earlier, I think it is worth looking at the Willie Davis method closely since some sources (particularly Baseball-Reference) use it for serious things like park-adjusting OPS+. This is in contrast to the position of its creator, Bill James, who presented it more as a toy that yields a rough estimate of what an equal value performance would look like in a different environment.
So, here are the OPS+ figures for the 1995 Rockies figured seven different ways. Let me note off the bat that I am using OBA = (H + W)/(AB + W); for this reason and the fact that I am using my own Coors PF, we should not anticipate exact agreement between these OPS+ results and the ones on Baseball-Reference. The league OBA in the 1995 NL was .328, and SLG was .408, so the basic formula for OPS+ is:
OPS+ = 100*(OBA/.328 + SLG/.408 - 1)
The first column of the table, "unadj" uses the player’s raw stats with no park adjustment. The second column, "trad", reflects the traditional method of figuring OPS+ used by Pete Palmer in The Hidden Game of Baseball, Total Baseball, and the ESPN Baseball Encyclopedia: simply divide OPS+ by the runs park factor (1.23) in this case.
The third column, "sqrt", adjusts OBA and SLG separately by dividing each by the square root of park factor, and uses these adjusted figures in the OPS+ formula above (*). The fourth column, "reg", uses the runs factor to estimate an OPS+ park factor based on a regression equation that relates OPS+ to adjusted runs/out (this is covered in the digression as well).
Finally there are three shaded columns, which use the translated OBA and SLG results from RC, ERP, and BsR respectively as the inputs into the OPS+ equations:

What can we see from this? The traditional approach is more severe than any of the Willie Davis approaches, while the square root approach is a pretty good match for the Willie Davis approaches. Thus, I suggest that the best combination of ease and accuracy in calculating OPS+ is to divide OBA and SLG by the square root of park factor, then plug the adjusted OBA and SLG into the OPS+ equation.
Of course, I should point out that 1995 Coors Field and its 1.23 park factor is one of the most extreme cases in the history of the game. For run of the mill environments, we should expect to see little difference regardless of how the park adjustments are applied, and so I am NOT saying that you should disregard the OPS+ figures on Baseball-Reference (although I do wish that OPS+ would be pushed aside in favor of better comprehensive rate stats). On the other hand, though, I see no reason to use a complicated park adjustment method like the Wille Davis approach when there are much easier approaches which we have some reason to believe better reflect true value.
(*) I shunted some topics down here into a digression because it covers a lot of ground that I’ve covered before and is even drier than what is above. And a lot of sabermetricians are sick and tired of talking about OPS, and I don’t blame them, so just skip this part if you don’t want to rehash it.
As I’ve explained before, OPS+ can be thought of as a quick approximation of runs/out. Some novice sabermetricians are surprised when they discover that OPS+ is adjusted OBA plus adjusted SLG minus one rather than OPS divided by league OPS. And it’s true that the name OPS+ can be misleading, but it is also true that it is a much better metric. One reason is that OPS/LgOPS does not have a 1:1 relationship with runs/out; it has a 2:1 relationship. If a team is 5% above the league average in OPS, your best guess is that they will score 10% more runs. So the OPS/LgOPS ratio has no inherent meaning; to convert it to an estimated unit, you would have to multiply by two and subtract one.
The other reason why OPS+ is superior is that it gives a higher weight to OBA. It doesn’t go far enough--the OBA weight should be something like 1.7 (assuming SLG is weighted at 1), while OPS+ only brings it up to around 1.2--insufficient, but still better than nothing.
Anyway, if you run a regression to estimate adjusted runs/out from OPS+, you find that it’s pretty close to a 1:1 relationship, particularly if you include HB in your OBA. I haven’t though, and so the relationship is something like 1.06(OPS+) - .06 = adjusted runs/out (again, it should be very close to 1:1 if you calculate OPS+ like a non-lazy person). The "reg" park adjustment, then, is to substitute the park factor for adjusted runs/out and solve for OPS+, giving an OPS+ park factor:
OPS+ park factor = (runs park factor + .06)/1.06
The slope of the line relating OPS+ to runs/out is not particularly steep, and so this is an almost negligible adjustment--for Coors Field and its 1.23 run park factor, we get a 1.217 OPS+ park factor.
Now a word about the traditional runs factor v. the individual square root adjustments. Since OPS+ is being used as a stand-in for run creation relative to the league average, I would assume that the goal in choosing a park adjustment approach is to provide the best match between adjusted OPS+ and adjusted runs/out. It turns out that if you figure relative ERP/Out for the ’95 Rockies players, the results are fairly consistent with the ERP/BsR translated OPS+. Thus, I am going to assume that those are the “best” adjusted OPS+ results, and that any simple park adjustment approach should hope to approximate them.
As a consequence, the square root adjustments to OBA and SLG look the best. Why is this? I’m not exactly sure; one might think that since OPS+ is a stand-in for relative runs/out, we should expect that the best adjustment approach once we already have unadjusted OPS+ is to divide by park factor. Yet we can get better results by adjusting each component individually by the square root of PF. OPS+ is far from a perfect approximation of relative runs/out, though, so it may not be that surprising that applying OPS+ logic to park factors is not quite optimal either.
Interestingly, the justification for the square root adjustment can be seen by looking at Runs Created in its OBA*SLG form. While OBA*SLG gives you an estimate of runs/at bat, not runs/out, it is of course related. If you take OBA/sqrt(PF)*SLG/sqrt(PF) you get OBA*SLG/(sqrt(PF)*sqrt(PF)) = OBA*SLG/PF
It is quite possible that there is a different power you could raise PF to that would provide a better match for our ERP-based OPS+ estimates, but getting any more in-depth would defeat the purpose of having a crude tool. In fact, I think that adjusting OPS+ by the Willie Davis method goes too far as well. Regardless, I would be remiss if I didn’t again emphasize that the 1995 Rockies are an extreme case, and so while the differences between the approaches may appear to be significant, they really aren’t 99% of the time.
Tuesday, July 26, 2016
The Willie Davis Method and OPS+ Park Factors
Subscribe to:
Post Comments (Atom)
No comments:
Post a Comment
I reserve the right to reject any comment for any reason.