A couple of caveats apply to everything that follows in this post. The first is that there are no park adjustments anywhere. There's obviously a difference between scoring 5 runs at Petco and scoring 5 runs at Coors, but if you're using discrete data there's not much that can be done about it unless you want to use a different distribution for every possible context. Similarly, it's necessary to acknowledge that games do not always consist of nine innings; again, it's tough to do anything about this while maintaining your sanity.
All of the conversions of runs to wins are based only on 2013 data. Ideally, I would use an appropriate distribution for runs per game based on average R/G, but I've taken the lazy way out and used the empirical data for 2013 only. (I have a methodology I could use to do estimate win probabilities at each level of scoring that take context into account, but I’ve not been able to finish the full write-up it needs on this blog before I am comfortable using it without explanation).
The first breakout is record in blowouts versus non-blowouts. I define a blowout as a margin of five or more runs. This is not really a satisfactory definition of a blowout, as many five-run games are quite competitive--"blowout” is just a convenient label to use, and expresses the point succinctly. I use these two categories with wide ranges rather than more narrow groupings like one-run games because the frequency and results of one-run games are highly biased by the home field advantage. Drawing the focus back a little allows us to identify close games and not so close games with a margin built in to allow a greater chance of capturing the true nature of the game in question rather than a disguised situational effect.
In 2013, 74.7% of major league games were non-blowouts while the complement, 25.3%, were. Team record in non-blowouts:

And in blowouts:

Teams sorted by difference between blowout and non-blowout W%, as well as the percentage of blowouts for each team:

Baltimore is one of the teams that interest me here; their unbelievable one-run record in 2012 was well-documented, and so it shouldn’t surprise that the Orioles ranked second in the majors in 2012 in non-blowout W% but were just over .500 in non-blowouts (23-21). In 2013, Baltimore just quit playing in blowouts, with only 15% of their games decided by five or more runs (only the White Sox at 17% joined them under 20% blowouts), but when they did they had a 14-11 record. Boston had the largest W% differential between blowouts and non-blowouts and were also the best team in the majors per most result-based perspectives.
A more interesting way to consider game-level results is to look at how teams perform when scoring or allowing a given number of runs. For the majors as a whole, here are the counts of games in which teams scored X runs:

The “marg” column shows the marginal W% for each additional run scored. In 2013, the second run was the marginally most valuable while the fourth was the cutoff point between winning and losing.
I use these figures to calculate a measure I call game Offensive W% (or Defensive W% as the case may be), which was suggested by Bill James in an old Abstract. It is a crude way to use each team’s actual runs per game distribution to estimate what their W% should have been by using the overall empirical W% by runs scored for the majors in the particular season.
A theoretical distribution would be much preferable to the empirical distribution for this exercise, but as I mentioned earlier I haven’t yet gotten around to writing up the requisite methodological explanation, so I’ve defaulted to the 2013 empirical data. Some of the drawbacks of this approach are:
1. The empirical distribution is subject to sample size fluctuations. In 2013, teams that scored 7 runs won 85.8% of the time while teams that scored 8 runs won 83.2% of the time. Does that mean that scoring 7 runs is preferable to scoring 8 runs? Of course not--it's a quirk in the data. Additionally, the marginal values don’t necessary make sense even when W% increases from one runs scored level to another (In figuring the gEW% family of measures below, I lumped all games with 7 and 8 runs scored/allowed into one bucket, which smoothes any illogical jumps in the win function, but leaves the inconsistent marginal values unaddressed and fails to make any differentiation between scoring 7 and 8. The values actually used are displayed in the “use” column, and the “invuse” column is the complements of these figures--i.e. those used to credit wins to the defense. I've used 1.0 for 12+ runs, which is a horrible idea theoretically. In 2013, teams were 102-0 when scoring 12 or more runs).
2. Using the empirical distribution forces one to use integer values for runs scored per game. Obviously the number of runs a team scores in a game is restricted to integer values, but not allowing theoretical fractional runs makes it very difficult to apply any sort of park adjustment to the team frequency of runs scored.
3. Related to #2 (really its root cause, although the park issue is important enough from the standpoint of using the results to evaluate teams that I wanted to single it out), when using the empirical data there is always a tradeoff that must be made between increasing the sample size and losing context. One could use multiple years of data to generate a smoother curve of marginal win probabilities, but in doing so one would lose centering at the season’s actual run scoring rate. On the other hand, one could split the data into AL and NL and more closely match context, but you would lose sample size and introduce more quirks into the data.
I will use my theoretical distribution (Enby, which you can read about here) for a few charts in this post. The first is a comparison of the frequency of scoring X runs in the majors to what would be expected given the overall major league average of 4.166 R/G (Enby distribution parameters are r = 3.922, B = 1.07, z = .0649):

Enby generally does a decent job of estimating the actual scoring distribution, and while I am certainly not an unbiased observer, I think it does so here as well.
I will not go into the full details of how gOW%, gDW%, and gEW% (which combines both into one measure of team quality) are calculated in this post, but full details were provided here. The “use” column here is the coefficient applied to each game to calculate gOW% while the “invuse” is the coefficient used for gDW%. For comparison, I have looked at OW%, DW%, and EW% (Pythagenpat record) for each team; none of these have been adjusted for park to maintain consistency with the g-family of measures which are not park-adjusted.
For most teams, gOW% and OW% are very similar. Teams whose gOW% is higher than OW% distributed their runs more efficiently (at least to the extent that the methodology captures reality); the reverse is true for teams with gOW% lower than OW%. The teams that had differences of +/- 2 wins between the two metrics were (all of these are the g-type less the regular estimate):
Positive: CHA, MIL, CHN, BAL, MIA, PIT, MIN
Negative: BOS, OAK, STL, TEX, CLE
There were an abnormally high number of teams this season whose gOW% diverged significantly from their standard OW%; as you’ll see in a moment, the opposite was true for gDW%. The White Sox gOW% of .467 was 3.5 games better than their OW% of .445. Their gOW% was seventh-lowest in the majors, but their OW% was second-worst. So while their offense was still bad, they wound up distributing their runs in a manner that should have resulted in more wins than one would expect from their R/G average.
As such, Chicago makes for an interesting case study in how a measly 3.69 runs/game can be doled out more efficiently. The black line is Chicago’s actual 2013 run distribution, the blue line is Enby’s estimate for a team averaging 3.691 R/G (r = 3.662, B = 1.018, z = .0853), and the red line is that of the majors as a whole (Chicago did not actually score more than twelve runs in a game this season, but fifteen is the standard I’ve always used in these graphs):

Chicago scored 3, 4, and 5 runs significantly more often than Enby would expect and more often that the major league average despite having a poor offense. 3-5 runs is a good spot to be in, at least in the current scoring environment--in 2013, teams won 54% of the time when scoring 3-5.
I deliberately wrote the preceding paragraph to be a little misleading--Chicago's propensity to score 3-5 runs was not really a positive, since it meant fewer games in which they scored more than five runs. The White Sox were shutout more often than the major league average (8% to 6.8%), scored < 2 runs more often than average (19.1% to 18%), but scored < 3 runs less often than average (50.6% to 47.8%). That is the only step at which Chicago was above average, and they quickly fell into well below average territory--Chicago scored < 6 runs 82% of the time versus the average of 71.9%:

Teams with differences of +/- 2 wins between gDW% and standard DW%:
Positive: SEA
Negative: ATL, TEX, OAK
The 3.7 win discrepancy between Atlanta’s gDW% (.570) and standard DW% (.592) was the largest such difference for any unit in the majors (greater than Chicago’s gOW% difference). The Braves were the only team which did not allow eleven or more runs in a game; the average was 3.4% and only Oakland (one) and St. Louis (two) had fewer than three such games. Avoiding those disaster games helped keep their RA/G low, but the Braves allowed four and five runs more often than both the Enby expectation for a team allowing 3.383 runs per game (r = 3.478, B = .983, z = .1023) would predict and the major league average:

Teams with differences of +/- 2 wins between gEW% and EW% (standard Pythagenpat):
Positive: SEA, CHA, PHI, PIT, MIN, CHN
Negative: OAK, TEX, STL, ATL, BOS, CLE, CIN
The negative list includes all playoff teams which obviously were not too badly hampered by seemingly inefficient run distributions. Standard Pythagenpat had a freakishly good year predicting actual W% in 2013, with a RMSE of 3.66 while gEW% had a 3.95 RMSE. gEW% does not incorporate any knowledge about the joint distribution of runs scored and allowed; if you do that, you may as well just look at actual win-loss record. But since it doesn’t have knowledge of the joint distribution, it’s quite possible for standard EW% to perform better as a predictor.
For now most of the applications of this methodology, at least in my writings, have been freak show in nature. The more interesting questions will be easier to investigate once I’ve finished my update of the Enby methodology. Do certain types of offenses tend to bunch their runs more efficiently? Can the estimate of variance of runs scored (which is really the key assumption underpinning Enby) be improved by considering team characteristics? How well do efficient or non-efficient distributions by teams predict team performance in future years? I don’t mean to imply that others have not investigated these questions, simply that I hope to have more interesting material in these year-end reviews starting in 2014. I said that last year too though.

Tuesday, January 28, 2014
Run Distribution and W%, 2013
Tuesday, January 14, 2014
Crude Team Ratings, 2013
For the last few years I have published a set of team ratings that I call "Crude Team Ratings". The name was chosen to reflect the nature of the ratings--they have a number of limitations, of which I documented several when I introduced the methodology.
I explain how CTR is figured in the linked post, but in short:
1) Start with a win ratio figure for each team. It could be actual win ratio, or an estimated win ratio.
2) Figure the average win ratio of the team’s opponents.
3) Adjust for strength of schedule, resulting in a new set of ratings.
4) Begin the process again. Repeat until the ratings stabilize.
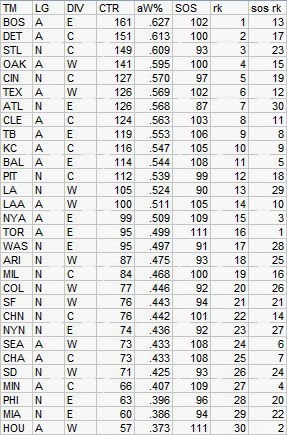
First, CTR based on actual wins and losses. In the table, “aW%” is the winning percentage equivalent implied by the CTR and “SOS” is the measure of strength of schedule--the average CTR of a team’s opponents. The rank columns provide each team’s rank in CTR and SOS:

This was a banner year for those of us who prefer the best teams to make it through the playoffs, as the pennant winners ranked one-two in MLB. The ten playoff teams were also the ten that had the most impressive win-loss records, with the exception of #9 Texas, but of course they had a shot in the one game playoff. Also, the Rangers were still only fifth in the AL so it’s not as if their schedule unfairly kept them out. What is a departure from recent seasons is that no other also-ran AL teams finished with higher ratings than the NL playoff qualifiers. Still, the AL dominated the top spots again as can be seen by the fact that only St. Louis snuck into the top five.
Below are the mean ratings for each league and division, actually calculated as the geometric rather than arithmetic mean:

Last year, the AL-NL gap was 112-89, and if you count Houston with the NL it was 106-88 in 2013. In any event, the AL remains the stronger league based on the interleague results (which is what underpins any differences in these rankings), with an implied W% of .521 against the NL.
Speaking of Houston, they actually ticked up a bit in CTR, from 46 to 48. While I wouldn’t claim that is a meaningful difference, it does indicate that their four win drop is largely a function of opponent quality, moving from the 21st most difficult schedule in 2012 to 4th in 2013. They also provide a good opportunity to point out that the schedule rankings are dependent on the quality of the team in question--Houston's schedule was tougher than that of their divisional opponents because they did not get the benefit of playing nineteen games against Houston.
Schedule can make a big difference when comparing two teams across leagues, in a tough and weak division--naturally, the largest schedule disparity is between the winner of the weakest division (NL East) and cellar dweller of the strongest (AL East). In the actual tallies, Atlanta was 96-66 and Toronto was 74-88. However, the ratings (as indicated by aW%) suggest that Atlanta was equivalent to a 92-70 team and Toronto to 78-84, an eight game swing in a head-to-head comparison. Atlanta’s SOS of 90 and Toronto’s of 112 implies that Toronto’s average opponent would have a .554 W% against Atlanta’s average opponent--comparable in 2013 CTR terms to the Dodgers or Rangers.
I will present the rest of the ratings with minimal comment. The next set is based on Pythagenpat record from R/RA:
Next is based on gEW%, which is explained in this post--some of the other exhibits for the annual post on that metric are a little more involved so I’m running these ratings first. The basic idea of gEW% is to take into account (separately) the distribution of runs scored and runs allowed per game for each team rather than simply using season totals as in Pythagenpat:

And finally, based on Runs Created and Allowed run through Pythagenpat:

These ratings are based on regular season data only, but one could also choose to include playoff results in the mix. Regardless of what your thoughts may be on the value of considering playoff data, it is most commonly omitted simply because of the way statistics are presented. It usually takes extra effort to combine regular season and playoff data.
So I decided to run the win-loss based ratings with playoff records and schedules included, and to see how large a difference it would create in the results. I was a little surprised by the results:

It’s not a surprise of course that Boston strengthened its rating--the Red Sox went 11-5 against very good competition. What did surprise me was that the only other playoff team to have a noticeable change in rating was Atlanta. Their 1-3 record against the Dodgers pushed their rating down by four points. Much of the movement in ratings for the other teams was felt by non-playoff teams whose SOS numbers fluctuated, in particular the AL East in which each team gained a point, and the NL in general, whose collective rating was pushed further down.
An angle that could make the playoff-inclusive ratings more interesting would be if I included regression in the ratings, which I do not. My reasoning is that I intend the ratings to be a reflection of the actual results of the season rather than an attempt to measure true quality of the teams. Additionally, regression would have little impact on the rank order of teams--it would mostly serve to compress the variance of the ratings. On the other hand, even if one wants to use the actual record of a team untouched to establish its rating, the case can be made that its opponents’ records should still be regressed, to avoid overcompensating for strength of schedule in ratings. Some purveyors of team ratings in other sports take a similar approach in basing calculations of opponent strength on those teams’ point-based rankings, but still base each team’s own rating on their actual wins and losses.
Again, though, these ratings are advertised as crude and are clearly only intended to be used in viewing 2013 retrospectively, so I’ve not bothered with regression here. I do use regression on the rare occasions when I use the CTRs to give crude estimates of win probabilities (such as playoff odds).