For the last several years I have published a set of team ratings that I call "Crude Team Ratings". The name was chosen to reflect the nature of the ratings--they have a number of limitations, of which I documented several when I introduced the methodology.
I explain how CTR is figured in the linked post, but in short:
1) Start with a win ratio figure for each team. It could be actual win ratio, or an estimated win ratio.
2) Figure the average win ratio of the team’s opponents.
3) Adjust for strength of schedule, resulting in a new set of ratings.
4) Begin the process again. Repeat until the ratings stabilize.
The resulting rating, CTR, is an adjusted win/loss ratio rescaled so that the majors’ arithmetic average is 100. The ratings can be used to directly estimate W% against a given opponent (without home field advantage for either side); a team with a CTR of 120 should win 60% of games against a team with a CTR of 80 (120/(120 + 80)).
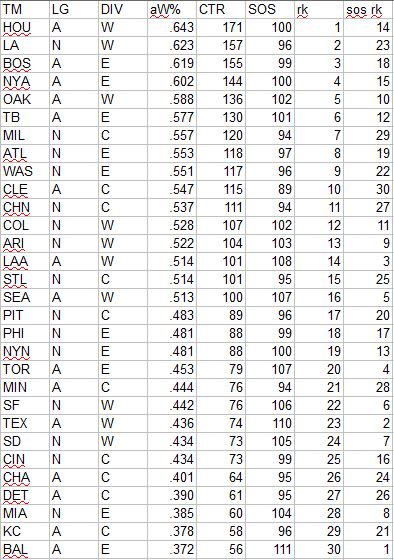
First, CTR based on actual wins and losses. In the table, “aW%” is the winning percentage equivalent implied by the CTR and “SOS” is the measure of strength of schedule--the average CTR of a team’s opponents. The rank columns provide each team’s rank in CTR and SOS:

The playoff teams all finished in the top twelve, with the third-place teams from the top-heavy AL East and West being denied spots in the dance despite having the fifth/sixth most impressive records in the majors (and damn the .3 CTR that separated us from #6org). The AL also had four of the bottom five teams; the bifurcated nature of the AL is something that was well observed and noted from the standings but also is evident when adjusting for strength of schedule. Note the hellish schedule faced by bad AL teams; Baltimore, with the worst CTR in MLB, had the toughest SOS at 118 - an average opponent at the level of the Cubs. Those Cubs had the easiest schedule, playing an average opponent roughly equivalent to the Pirates.
Next are the division averages. Originally I gave the arithmetic average CTR for each division, but that’s mathematically wrong--you can’t average ratios like that. Then I switched to geometric averages, but really what I should have done all along is just give the arithmetic average aW% for each division/league. aW% converts CTR back to an “equivalent” W-L record, such that the average across the major leagues will be .50000:

The AL once again was markedly superior to the NL; despite the sorry showing of the Central, the West was almost as good as it was bad, and the East was strong as well. Given the last fifteen years of AL dominance, you may have glossed over the last sentence, but if you are familiar with the results of 2018 interleague play, it may give you pause. The NL went 158-142 against the AL, so how does the average AL team rank ahead? It may be counter-intuitive, but one can easily argue that the NL should have performed better than it did. The NL’s best division got the benefit of matching up with the AL’s worst division (the Centrals). The AL Central went 38-62 (.380), but the East went 54-46 (.540) and the West 50-50 (.500).
Of course, the CTRs can also use theoretical win ratios as a basis, and so the next three tables will be presented without much comment. The first uses gEW%, which is a measure I calculate that looks at each team’s runs scored distribution and runs allowed distribution separately to calculate an expected winning percentage given average runs allowed or runs scored, and then uses Pythagorean logic to combine the two and produce a single estimated W% based on the empirical run distribution:

The next version utilizes EW%, which is to say standard Pythagenpat based on actual runs scored and allowed:

And one based on PW%, which is Pythagenpat but using runs created and runs created allowed in place of actual runs totals:
Everything that I’ve shared so far has been based on regular season data only. Of course, ten teams play additional games for keeps, and we could consider these in ratings as well. Some points to consider when it comes to incorporating postseason data:
1. It would be silly to pretend that these additional games don’t give us any insight on team quality. Of course every opportunity we have to observe a team in a competitive situation increases our sample size and informs our best estimate of that team’s quality.
2. Postseason games are played under a different set of conditions and constraints than regular season games, particularly when it comes to how pitchers are used. This is not a sufficient reason to ignore the data, in my opinion.
3. A bigger problem, and one that causes me to present ratings that include postseason performance only half-hardheartedly, is the bias introduced to the ratings by the playoff structure. The nature of postseason series serves to exaggerate the difference in team performance observed during the series. Take the Astros/Indians ALCS. The Astros dominated the Indians over three games, which certainly provides additional evidence vis-a-vis the relative strength of the two teams. Based on regular season performance, Houston looked like a superior club (175 to 113 CTR, implying that they should win 61% of their games against the Indians), and the sweep provided additional evidence. However, because the series terminated after three games, all won by the Astros, it overstated the difference. If the series was played out to completion (assuming you can imagine a non-farcial way in which this could be done), we would expect to see Cleveland pull out a win, and even adding 1-4 and 4-1 to these two team’s ratings would decrease the CTR gap between the two (although still correctly increasing it compared to considering only the regular season).
This is one of those concepts that seems very clear to me when I think about it, and yet is extremely difficult to communicate in a coherent manner, so let me simply assert that I think bias is present when the number of observations is dependent on the outcome of the previous observations (like in a playoff series) that is not present when the number of observations is independent of the outcome of previous observations (as is the case for a regular season in which all teams play 162 games regardless of whether they are mathematically eliminated in August).
Still, I think it’s worth looking at CTRs including the post-season; I only will present these for actual wins and losses, but of course if you were so inclined you could base them on estimated winning percentages as well:

Here is a comparison of CTR including postseason (pCTR) to the regular season-only version, and the difference between the two:

I’ve been figuring CTRs since 2011 and playoff-inclusive versions since 2013, so Boston’s rating in both stood out when I saw it. I thought it might be interesting to look at the leader in each category each season. The 2018 Red Sox are the highest-rated team of the past eight seasons by a large margin (of course, such ratings do nothing to estimate any kind of underlying differences in MLB-wide quality between seasons):

I didn’t realize that the 2017 Dodgers were the previous leaders; I would have guessed it was the 2016 Cubs, although they would be much farther down the list. It is also worth noting that this year’s Astros would have been ranked #1 of the period were it not for the Red Sox. Boston’s sixteen point improvement including the playoffs was easily the best for any team that had been ranked #1, and that does make sense intuitively: 3-1 over the #3 ranked (regular season) Yankees, 4-1 over #2 ranked Houston, and 4-1 over the #9 Dodgers is one impressive playoff showing.
Tuesday, December 18, 2018
Crude Team Ratings, 2018
Monday, December 10, 2018
Hitting by Position -- 2018
Of all the annual repeat posts I write, this is the one which most interests me--I have always been fascinated by patterns of offensive production by fielding position, particularly trends over baseball history and cases in which teams have unusual distributions of offense by position. I also contend that offensive positional adjustments, when carefully crafted and appropriately applied, remain a viable and somewhat more objective competitor to the defensive positional adjustments often in use, although this post does not really address those broad philosophical questions.
The first obvious thing to look at is the positional totals for 2018, with the data coming from Baseball-Reference.com. "MLB” is the overall total for MLB, which is not the same as the sum of all the positions here, as pinch-hitters and runners are not included in those. “POS” is the MLB totals minus the pitcher totals, yielding the composite performance by non-pitchers. “PADJ” is the position adjustment, which is the position RG divided by the overall major league average (this is a departure from past posts; I’ll discuss this a little at the end). “LPADJ” is the long-term positional adjustment that I use, based on 2002-2011 data. The rows “79” and “3D” are the combined corner outfield and 1B/DH totals, respectively:

An annual review of this data is problematic because it can lead to seeing trends where there are actually just blips. Two years ago second basemen smashed their way to unprecedented heights; this year they were right back at their long-term average. In 2017, DHs were 4% worse than the league average -- in 2018 they were part of what one could call the left side convergence of the defensive spectrum, as DH, 1B, LF, RF, and 3B all basically hit the same. Shortstops were above league average, which is of note, while catchers and center fielders also ended up right at their normal levels (yes, I really should update my “long-term” positional adjustments; I promise to do that for next year).
Moving on to looking at more granular levels of performance, I always start by looking at the NL pitching staffs and their RAA. I need to stress that the runs created method I’m using here does not take into account sacrifices, which usually is not a big deal but can be significant for pitchers. Note that all team figures from this point forward in the post are park-adjusted. The RAA figures for each position are baselined against the overall major league average RG for the position, except for left field and right field which are pooled.

While positions relative to the league bounce around each year, it seems that the most predictable thing about this post is that the difference between the best and worst NL pitching staffs will be about twenty runs at the plate. Sixteen is a narrower spread than typical, but pitchers also fell to an all-time low -5 positional adjustment.
I don’t run a full chart of the leading positions since you will very easily be able to go down the list and identify the individual primarily responsible for the team’s performance and you won’t be shocked by any of them, but the teams with the highest RAA at each spot were:
C--LA, 1B--LA, 2B--HOU, 3B--CLE, SS--BAL, LF--MIL, CF--LAA, RF--BOS, DH--NYA
I don’t know about “shocked”, but I was surprised to see that Baltimore had the most productive shortstops. Not that I didn’t know that Manny Machado had a great “first half” of the season for the O’s, but I was surprised that whoever they threw out there for the rest of the year didn’t drag their overall numbers down further. In fact Tim Beckham and Jonathan Villar were perfectly cromulent (offensively at least, although Machado wasn’t lighting up any defensive metrics himself) and Baltimore finished two RAA ahead of the Red Sox (Bogaerts) and Indians (Lindor), and three runs ahead of the Rockies (Story).
More interesting are the worst performing positions; the player listed is the one who started the most games at that position for the team:

Boston’s catchers weren’t the worst relative to their position, but they were the worst hitting regular position in MLB on a rate basis; teams can certainly overcome a single dreadful position, but they usually don’t do it to the tune of 108 wins. The most pathetic position was definitely the Orioles’ first basemen, with a healthy lead for lowest RAA thanks to having the fifth-worst RG of any regular position (only Red Sox catchers, Tigers second basemen, Diamondback catchers, and their own catchers were worse).
I like to attempt to measure each team’s offensive profile by position relative to a typical profile. I’ve found it frustrating as a fan when my team’s offensive production has come disproportionately from “defensive” positions rather than offensive positions (“Why can’t we just find a corner outfielder who can hit?”) The best way I’ve yet been able to come up with to measure this is to look at the correlation between RG at each position and the long-term positional adjustment. A positive correlation indicates a “traditional” distribution of offense by position--more production from the positions on the right side of the defensive spectrum. (To calculate this, I use the long-term positional adjustments that pool 1B/DH as well as LF/RF, and because of the DH I split it out by league.) There is no value judgment here--runs are runs whether they are created by first basemen or shortstops:

We’ve already seen that Milwaukee’s shortstops were the least productive in the majors and their left fielders the most productive, which helps explain their high correlation. Baltimore’s low correlation likewise makes sense as they had the least productive first basemen and the most productive shortstops.
The following tables, broken out by division, display RAA for each position, with teams sorted by the sum of positional RAA. Positions with negative RAA are in red, and positions that are +/-20 RAA are bolded:

Boston’s monstrously productive outfield easily led the majors in RAA (as did their corner outfielders), but the catchers dragged them down just behind New York. Baltimore was below-average at every position except shortstop, so after they dealt Machado it was really ugly. They were the worst in MLB at both the infield and outfield corners.

Cleveland’s offense had issues all over the place, but a pair of MVP candidates on the infield can cover that up, at least in the AL Central where every other team was below average. Chicago had the major’s worst outfield RAA while Detroit was last in the AL for middle infielders.

For a second straight season, Houston’s infield and middle infield were tops in the AL despite injuries slowing down Altuve and Correa. Oakland’s Matts led the majors in corner infield RAA. Los Angeles had the majors least productive infield, which for all its badness still couldn’t cancel out the Trout-led centerfielders.

Washington led the NL in corner outfield RAA. New York was last in the NL in corner infield RAA. Last year Miami led the majors in outfield RAA; this year they trailed. This comes as no surprise of course, but is still worthy of a sad note before chuckling at the dark, monochromatic threads they will wear in 2019.

This division was nearly the opposite of the AL Central, as every team had a positive RAA with room to spare. Chicago lead the majors in middle infield RAA; Milwaukee was the worst in the same category, but covered it over with the NL’s most productive outfield. I will admit to being as confused by their trade deadline manueverings at the next guy, but when you see so starkly how little they were getting out of their middle infield, the shakeup makes more sense. Of course one of the chief regular season offenders Orlando Arcia raked in the playoffs.

Los Angeles’ corner infielders led the majors in RAA, and dragged their middle infielders (well, really just the second basemen) to the best total infield mark as well. The rest of the division was below average, and Colorado’s corner outfielders were last in the NL which should provide a juicy career opportunity for someone.
The full spreadsheet with data is available here.
Monday, November 19, 2018
Leadoff Hitters, 2018
I will try to make this as clear as possible: the statistics are based on the players that hit in the #1 slot in the batting order, whether they were actually leading off an inning or not. It includes the performance of all players who batted in that spot, including substitutes like pinch-hitters.
Listed in parentheses after a team are all players that started in twenty or more games in the leadoff slot--while you may see a listing like "HOU (Springer)" this does not mean that the statistic is only based solely on Springers's performance; it is the total of all Houston batters in the #1 spot, of which Springer was the only one to start in that spot in twenty or more games. I will list the top and bottom three teams in each category (plus the top/bottom team from each league if they don't make the ML top/bottom three); complete data is available in a spreadsheet linked at the end of the article. There are also no park factors applied anywhere in this article.
That's as clear as I can make it, and I hope it will suffice. I always feel obligated to point out that as a sabermetrician, I think that the importance of the batting order is often overstated, and that the best leadoff hitters would generally be the best cleanup hitters, the best #9 hitters, etc. However, since the leadoff spot gets a lot of attention, and teams pay particular attention to the spot, it is instructive to look at how each team fared there.
The conventional wisdom is that the primary job of the leadoff hitter is to get on base, and most simply, score runs. It should go without saying on this blog that runs scored are heavily dependent on the performance of one’s teammates, but when writing on the internet it’s usually best to assume nothing. So let's start by looking at runs scored per 25.5 outs (AB - H + CS):
1. BOS (Betts/Benintendi), 9.0
2. STL (Carpenter/Pham), 7.1
3. NYA (Gardner/Hicks/McCutchen), 6.8
Leadoff average, 5.4
ML average, 4.4
28. SF (Hernandez/McCutchen/Blanco/Panik), 4.1
29. SD (Jankowski, Margot), 4.1
30. BAL (Mancini/Mullens/Beckham), 4.0
In the years I’ve been writing this post, I’m not sure I’ve since the same player show up as a member of a leading team and a atrailing team, but there is Andrew McCutchen, part-time leadoff hitter for both the group that scored runs as the third-highest clip and at the third-lowest. Leading off just 28 times for the Giants and 21 times for the Yankees, he wasn’t the driving force behind either performance.
The most basic team independent category that we could look at is OBA (figured as (H + W + HB)/(AB + W + HB)):
1. BOS (Betts/Benintendi), .421
2. CHN (Almora/Rizzo/Murphy/Zobrist), .367
3. KC (Merrifield/Jay), .365
Leadoff average, .335
ML average, .320
28. BAL (Mancini/Mullens/Beckham), .297
29. DET (Martin/Candelario), .296
30. SF (Hernandez/McCutchen/Blanco/Panik), .294
I’m still lamenting the loss of “Esky Magic” as a punchline for every leaderboard in this post, even though it’s been two years since the Royals leadoff spot was making outs in bunches thanks to their magical shortstop. Luckily Whit Merrifield gives off scrappy player vibes that media narrative makers can get behind...well, could if anyone still cared about the Royals.,
The next statistic is what I call Runners On Base Average. The genesis for ROBA is the A factor of Base Runs. It measures the number of times a batter reaches base per PA--excluding homers, since a batter that hits a home run never actually runs the bases. It also subtracts caught stealing here because the BsR version I often use does as well, but BsR versions based on initial baserunners rather than final baserunners do not. Here ROBA = (H + W + HB - HR - CS)/(AB + W + HB).
This metric has caused some confusion, so I’ll expound. ROBA, like several other methods that follow, is not really a quality metric, it is a descriptive metric. A high ROBA is a good thing, but it's not necessarily better than a slightly lower ROBA plus a higher home run rate (which would produce a higher OBA and more runs). Listing ROBA is not in any way, shape or form a statement that hitting home runs is bad for a leadoff hitter. It is simply a recognition of the fact that a batter that hits a home run is not a baserunner. Base Runs is an excellent model of offense and ROBA is one of its components, and thus it holds some interest in describing how a team scored its runs. As such it is more a measure of shape than of quality:
1. BOS (Betts/Benintendi), .360
2. KC (Merrifield/Jay), .338
3. CHN (Almora/Rizzo/Murphy/Zobrist), .334
Leadoff average, .298
ML average, .285
28. BAL (Mancini/Mullens/Beckham), .264
29. SF (Hernandez/McCutchen/Blanco/Panik), .259
30. LAA (Calhoun/Kinsler/Cozart), .257
The Angels are the only change from the top/bottom three on the OBA list; they were fourth-last at .298 but their 26 homers eighth and drove their ROBA down to the bottom.
I also include what I've called Literal OBA--this is just ROBA with HR subtracted from the denominator so that a homer does not lower LOBA, it simply has no effect. It “literally” (not really, thanks to errors, out stretching, caught stealing after subsequent plate appearances, etc.) is the proportion of plate appearances in which the batter becomes a baserunner able to be advanced by his teammates. You don't really need ROBA and LOBA (or either, for that matter), but this might save some poor message board out there twenty posts, by not implying that I think home runs are bad. LOBA = (H + W + HB - HR - CS)/(AB + W + HB - HR):
1. BOS (Betts/Benintendi), .379
2. KC (Merrifield/Jay), .343
3. CHN (Almora/Rizzo/Murphy/Zobrist), .343
Leadoff average, .306
ML average, .294
28. BAL (Mancini/Mullens/Beckham), .271
29. LAA (Calhoun/Kinsler/Cozart), .267
30. SF (Hernandez/McCutchen/Blanco/Panik), .266
The next two categories are most definitely categories of shape, not value. The first is the ratio of runs scored to RBI. Leadoff hitters as a group score many more runs than they drive in, partly due to their skills and partly due to lineup dynamics. Those with low ratios don’t fit the traditional leadoff profile as closely as those with high ratios (at least in the way their seasons played out, and of course using R and RBI incorporates the quality and style of the hitters in the adjacent lineup spots rather then attributes of the leadoff hitters’ performance in isolation):
1. SEA (Gordon/Haniger), 2.0
2. MIL (Cain/Thames), 1.9
3. MIA (Dietrich/Castro/Ortega), 1.9
Leadoff average, 1.6
28. WAS (Eaton/Turner), 1.3
29. ATL (Acuna/Inciarte/Albies), 1.3
30. TOR (Granderson/McKinney), 1.2
ML average, 1.0
I don’t know about you, but if you’d told me that leadoff spots led by Cain/Thames and Eaton/Turner would both appear as extreme on this list, I would have guessed that the former would be the one tilted to RBI.
A similar gauge, but one that doesn't rely on the teammate-dependent R and RBI totals, is Bill James' Run Element Ratio. RER was described by James as the ratio between those things that were especially helpful at the beginning of an inning (walks and stolen bases) to those that were especially helpful at the end of an inning (extra bases). It is a ratio of "setup" events to "cleanup" events. Singles aren't included because they often function in both roles.
Of course, there are RBI walks and doubles are a great way to start an inning, but RER classifies events based on when they have the highest relative value, at least from a simple analysis:
1. PHI (Hernandez), 1.4
2. KC (Merrifield/Jay), 1.3
3. TB (Smith/Kiermaier/Span), 1.1
Leadoff average, .8
ML average, .7
28. LA (Taylor/Pederson), .6
29. PIT (Frazier/Harrison/Dickerson), .5
30. TOR (Granderson/McKinney), .5
I should note that in the context-neutral RER, the two teams with seemingly backwards placement on the R/RBI list are closer to where you’d expect--the Nats were sixth at 1.0 while the Brewers were still forwardly placed but much closer to average (ranking tenth with .9).
Since stealing bases is part of the traditional skill set for a leadoff hitter, I've included the ranking for what some analysts call net steals, SB - 2*CS. I'm not going to worry about the precise breakeven rate, which is probably closer to 75% than 67%, but is also variable based on situation. The ML and leadoff averages in this case are per team lineup slot:
1. WAS (Eaton/Turner), 26
2. KC (Merrifield/Jay), 25
3. TB (Smith/Kiermaier/Span), 17
Leadoff average, 5
ML average, 2
27. BAL (Mancini/Mullens/Beckham), -6
27. CHN (Almora/Rizzo/Murphy/Zobrist), -6
27. LA (Taylor/Pederson), -6
30. CIN (Peraza/Schebler/Winker/Hamilton), -9
Shifting back to quality measures, first up is one that David Smyth proposed when I first wrote this annual leadoff review. Since the optimal weight for OBA in a x*OBA + SLG metric is generally something like 1.7, David suggested figuring 2*OBA + SLG for leadoff hitters, as a way to give a little extra boost to OBA while not distorting things too much, or even suffering an accuracy decline from standard OPS. Since this is a unitless measure anyway, I multiply it by .7 to approximate the standard OPS scale and call it 2OPS:
1. BOS (Betts/Benintendi), 1017
2. CLE (Lindor), 847
3. STL (Carpenter/Pham), 842
Leadoff average, 762
ML average, 735
28. SF (Hernandez/McCutchen/Blanco/Panik), 669
29. DET (Martin/Candelario), 652
30. BAL (Mancini/Mullens/Beckham), 649
Along the same lines, one can also evaluate leadoff hitters in the same way I'd go about evaluating any hitter, and just use Runs Created per Game with standard weights (this will include SB and CS, which are ignored by 2OPS):
1. BOS (Betts/Benintendi), 8.7
2. CLE (Lindor), 5.9
3. STL (Carpenter/Pham), 5.7
Leadoff average, 4.7
ML average, 4.3
28. SF (Hernandez/McCutchen/Blanco/Panik), 3.5
29. DET (Martin/Candelario), 3.3
30. BAL (Mancini/Mullens/Beckham), 3.1
Seeing the same six extreme teams in perfect order overstates the correlation, but naturally there is a very strong relationship between the last two metrics. The biggest difference in any team’s ranks in the two was four spots.
Allow me to close with a crude theoretical measure of linear weights supposing that the player always led off an inning (that is, batted in the bases empty, no outs state). There are weights out there (see The Book) for the leadoff slot in its average situation, but this variation is much easier to calculate (although also based on a silly and impossible premise).
The weights I used were based on the 2010 run expectancy table from Baseball Prospectus. Ideally I would have used multiple seasons but this is a seat-of-the-pants metric. The 2010 post goes into the detail of how this measure is figured; this year, I’ll just tell you that the out coefficient was -.234, the CS coefficient was -.601, and for other details refer you to that post. I then restate it per the number of PA for an average leadoff spot (748 in 2017):
1. BOS (Betts/Benintendi), 57
2. STL (Carpenter/Pham), 20
3. CLE (Lindor), 17
Leadoff average, 0
ML average, -7
28. SF (Hernandez/McCutchen/Blanco/Panik), -22
29. DET (Martin/Candelario), -24
30. BAL (Mancini/Mullens/Beckham), -27
Boston completely dominated the quality metrics for leadoff hitters in 2018, due mostly of course to the superlative season of Mookie Betts, who was the second-best offensive player in the game in 2018. Put one of the top hitters in the leadoff spot and you can expect to lead in a lot of categories - BOS led easily not just in categories that reflect quality without any shape distortion (not necessarily context-free) like R/G, OBA, 2OPS, RG, and LE, but also in ROBA and LOBA, which are designed to not measure value but rather the rate of leadoff hitters reaching base for their teammates to drive in. What’s more, it’s not as if Boston achieved this by having a really good OBA out of the leadoff spot without a lot of power - the Red Sox and Cardinals tied for the ML league with 38 homers out of the leadoff spot. The Indians ranked third with 37, and those teams ranked 1-2-3 in all of the overall quality measures. One can argue about optimal lineup construction, but in 2018, leadoff hitters hit dingers like everyone else. Every team was in double digits in homers out of the leadoff spot; in 2017 there were only two, but one of those teams hit just three homers.
The spreadsheet with full data is available here.
Monday, November 12, 2018
Hypothetical Ballot: MVP
I tend to think I’m pretty objective when it comes to baseball analysis. Someone reading my blog or Twitter feed (RIP, mostly) with a critical eye might beg to differ: I like the Indians, players accused of using steroids, hate the Royals, and oh yeah I really love Mike Trout. The latter is certainly not unique to me -- how could you not like Mike Trout? -- but it is pronounced enough that my objectivity could be called into question when (for once) Mike Trout is engaged in a close race for AL MVP.
I think Mike Trout was most likely the most valuable player in baseball in 2018, and I firmly believe I would say that even if I was not a huge fan. While Baseball-Reference and Fangraphs’ WAR would disagree, Baseball Prospectus’ WARP agrees, so I’m not completely on an island.
The key consideration for me is that Trout was markedly superior offensively to Mookie Betts once you properly weight offensive events (read: more credit to Trout for his walks than metrics of the OPS family would allow) and adjust for the big difference in park factors between Angels Stadium and Fenway Park (97 and 105 PF respectively). I estimate that, adjusting for park, Trout created six more runs than Betts while making twenty fewer outs. That’s about a nine run difference. Then there is the position adjustment, which is worth another four.
Betts does cut into this lead with his defensive value: going in the order FRAA/UZR/DRS, Betts (11/15/20) has an average twelve runs higher than Trout (-2/4/8). I don’t credit the full difference, but even if I did, Trout would still have a one run edge. Give Betts a couple extra runs for baserunning (a debatable point)? I’m still going with the player with a clear advantage in offensive value. Regress the defense 50%? It’s close but the choice is much clearer.
The rest of my ballot is pretty self-explanatory if you look at my RAR estimates. I could justify just about any order of 6-9; I’m not at all convinced that JD Martinez was more valuable than Jose Ramirez, but chalk that one up to avoiding the indication of bias. Francisco Lindor rises based on excellent fielding metrics (6/14/14):
1. CF Mike Trout, LAA
2. RF Mookie Betts, BOS
3. SP Justin Verlander, HOU
4. 3B Alex Bregman, HOU
5. SP Chris Sale, BOS
6. DH JD Martinez, BOS
7. SP Blake Snell, TB
8. SS Francisco Lindor, CLE
9. 3B Jose Ramirez, CLE
10. SP Corey Kluber, CLE
The NL MVP race is weird. Christian Yelich had an eighteen RAR lead over the next closest position player (Javier Baez), which is typically an indication of a historically great season. Triple crown bid aside, Yelich did not have a historically great season, “merely” a typical MVP-type season. In the AL, he would have been well behind Trout and Betts with Bregman and Martinez right on his heels.
Thus the only meaningful comparison for the top of the ballot is the top hitter (Yelich) against the top pitcher (Jacob deGrom). When it comes to an MVP race between a hitter and a pitcher, I usually try to give the former the benefit of the doubt. Specifically, while there is one primary way in which I evaluate the offensive contribution of a hitter (runs created based on their statistics, converted to RAR), there are three obvious ways using the traditional stat line to calculate RAR for a pitcher. The first is based on actual runs allowed; the second on peripheral statistics (this one is most similar to the comparable calculation for batters); the third based on DIPS principle. In order for me to support a pitcher for MVP, ideally he would be more valuable using each of these perspectives on evaluating performance. deGrom achieved this, with his lowest RAR total (72 based on DIPS principles) exceeding Yelich’s 69 RAR (and with Yelich’s -5/-2/4 fielding metrics, 69 is as good as it gets).
Given the huge gap between Yelich and Baez, starting pitchers dominate the top of my ballot. The movers upward when considering fielding are a pair of first basemen (Freddie Freeman and Paul Goldschmidt) and Nolan Arenado, while Bryce Harper’s fielding metrics were dreadful (-12/-14/-26) and drop him all the way off the ballot:
1. SP Jacob deGrom, NYN
2. LF Christian Yelich, MIL
3. SP Max Scherzer, WAS
4. SP Aaron Nola, PHI
5. SP Kyle Freeland, COL
6. SP Patrick Corbin, ARI
7. SS Javier Baez, CHN
8. 1B Freddie Freeman, ATL
9. 1B Paul Goldschmidt, ARI
10. 3B Nolan Arenado, COL
Thursday, November 08, 2018
Hypothetical Ballot: Cy Young
The AL Cy Young race is extremely close due to the two candidates who appeared to be battling it out for the award much of the season missing significant time in the second half. Despite their injuries, Chris Sale and Trevor Bauer had logged enough innings preventing enough runs on a rate basis to still be legitimate contenders in the end. Justin Verlander and Blake Snell each tied with 74 RAR based on actual runs allowed adjusted for bullpen support, an eight run lead over Sale in third. But when you look at metrics based on eRA (based on “components”) and dRA (based on DIPS concepts), Sale, Bauer, Corey Kluber, and Gerrit Cole all cut into that gap.
In fact, using a crude weighting of 50% RA-based, 25% eRA-based, and 25% dRA-based RAR, there are six pitchers separated by seven RAR. A seventh, Mike Clevinger, had 65 standard RAR but worse peripherals to drop four runs behind the bottom of that pack.
There are any number of reasonable ways to fill out one’s ballot, but I think the best choice for across-the-board excellence is Verlander. He pitched just one fewer inning than league leader Kluber, tied for the league lead in standard RAR, was second one run behind Kluber in eRA-based RAR, and was third by five runs to Sale in dRA-based RAR. Chris Sale sneaks into second for me as he led across the board in RA; even pitching just 158 innings, seventeen fewer than even Bauer, his excellence allowed him to accrue a great deal of value. Snell and the Indians round out my ballot; I’ve provided the statistics I considered below as evidence of how close this is:
1. Justin Verlander, HOU
2. Chris Sale, BOS
3. Blake Snell, TB
4. Corey Kluber, CLE
5. Trevor Bauer, CLE

The NL race is not nearly as close, as Jacob deGrom was second in innings (by just three to Max Scherzer) and led in all of the RA categories, plus Quality Start % and probably a whole bunch of equally suspect measures of performance.
Behind him I see no particular reason to deviate from the order suggested by RAR; Scherzer over Aaron Nola is an easy choice due to the former’s superior peripherals, and while Patrick Corbin had superior peripherals to Kyle Freeland, the latter’s 13 RAR lead is a lot to ignore, although Corbin should be recognized for having an eRA and dRA quite similar to Max Scherzer and otherwise lapping the rest of the field. With the exception of course of Jacob deGrom, the author a season that is worthy of considerable discussion in the next installment of “meaningless hypothetical award ballots”:
1. Jacob deGrom, NYN
2. Max Scherzer, WAS
3. Aaron Nola, PHI
4. Kyle Freeland, COL
5. Patrick Corbin, ARI
Wednesday, October 31, 2018
Hypothetical Ballot: Rookie of the Year
I would expect to see some fairly wide variations in Rookie of the Year rankings even among sabermetric-minded people this season, especially in the American League where nuances in player value methodology can result in significant differences in how ones ranks the candidates.
I think that Shohei Ohtani was the most valuable AL rookie, by a decent margin. Offensively, I have him at 28 RAR; you may want to cut a few runs off of that if you think there should be a more punitive DH penalty. That ranks behind Miguel Andujar (36) and Joey Wendle (31), and even with Gleybar Torres (27). However, Andujar’s fielding marks are truly dreadful (-11 BP FRAA is the most generous evaluation; UZR at -16 and DRS at -25 are even more down on his performance). Wendle consistently gets around 5 RAA, and evaluations of Torres are varied (7, -8, -1).
Ohtani also contributed as a pitcher. While he only pitched 52 innings, his 3.41 park-adjusted RA over that work is good for 14 RAR. I see no reason why he shouldn’t be viewed separately against replacement level for his offensive and pitching work; this isn’t the same situation as evaluating a batter against separate replacement levels for offense and fielding. Ohtani’s role can be bifurcated by his manager; if he was not contributing value offensively, he would lose his opportunities in that space while still being permitted to take the mound. A player’s performance as a batter and a fielder cannot be similarly divided, except if the DH role is available. If anything, Ohtani should get a bonus for only taking up one roster spot (can we use that to offset any docking for the DH positional adjustment and call it even?)
Ohtani at 42 RAR outshines Wendle, even with full credit for fielding, as well as the top pitching candidate, Brad Keller (36 RAR with a good eRA but only 28 RAR if evaluated on a DIPS basis). The other top pitching candidate by standard RAR, Jamie Barria (33), had worse peripherals and a very poor dRA (5.24). Regressing the fielding stats a little, I give Andujar the nod over Torres with offense as tiebreaker, but they should be the bottom of the ballot, not the top:
1. DH/SP Shohei Ohtani, LAA
2. 3B Joey Wendle, TB
3. SP Brad Keller, KC
4. 3B Miguel Andujar, NYA
5. 2B Gleyber Torres, NYA
In the NL, the old pull to bestow RoY upon the transcendent prospect rather than the most valuable rookie comes into play a little bit. With two young hitters the caliber of Ronald Acuna and Juan Soto to choose from, it is very tempting to put them on top. I think Walker Buehler deserves better. At 43 RAR, Buehler is ahead of Acuna and Soto (38) before taking fielding into account, and neither Acuna (-2 to -9) or Soto (3 to -5) shine in those metrics.
I think the three can be placed in any ballot order quite reasonably; while most people (including me) would take Acuna’s future, Soto and Acuna were nearly even this season, with essentially the same park-adjusted batting averages supplemented by Soto’s amazing walk rate and Acuna’s superior power. Give Soto some credit as a fielder and Acuna some as a baserunner and it’s still very close. Buehler was not as strong in RAR if using a DIPS approach (30), which drops him back to their level. Acuna may be the better prospect, but Soto’s younger, and while I don’t like to give extra credit for performance by time in the season, Buehler came up huge in a regular season game that would conclusively decide a division title. Somewhat arbitrarily, I have it:
1. LF Juan Soto, WAS
2. SP Walker Buehler, LA
3. LF Ronald Acuna, ATL
4. SP Jack Flaherty, STL
5. RF Brian Anderson, MIA
Friday, October 05, 2018
End of Season Statistics, 2018
The spreadsheets are published as Google Spreadsheets, which you can download in Excel format by changing the extension in the address from "=html" to "=xlsx", or in open format as "=ods". That way you can download them and manipulate things however you see fit.
The data comes from a number of different sources. Most of the data comes from Baseball-Reference. KJOK's park database is extremely helpful in determining when park factors should reset. Data on bequeathed runners comes from Baseball Prospectus.
The basic philosophy behind these stats is to use the simplest methods that have acceptable accuracy. Of course, "acceptable" is in the eye of the beholder, namely me. I use Pythagenpat not because other run/win converters, like a constant RPW or a fixed exponent are not accurate enough for this purpose, but because it's mine and it would be kind of odd if I didn't use it.
If I seem to be a stickler for purity in my critiques of others' methods, I'd contend it is usually in a theoretical sense, not an input sense. So when I exclude hit batters, I'm not saying that hit batters are worthless or that they *should* be ignored; it's just easier not to mess with them and not that much less accurate (note: hit batters are actually included in the offensive statistics now).
I also don't really have a problem with people using sub-standard methods (say, Basic RC) as long as they acknowledge that they are sub-standard. If someone pretends that Basic RC doesn't undervalue walks or cause problems when applied to extreme individuals, I'll call them on it; if they explain its shortcomings but use it regardless, I accept that. Take these last three paragraphs as my acknowledgment that some of the statistics displayed here have shortcomings as well, and I've at least attempted to describe some of them in the discussion below.
The League spreadsheet is pretty straightforward--it includes league totals and averages for a number of categories, most or all of which are explained at appropriate junctures throughout this piece. The advent of interleague play has created two different sets of league totals--one for the offense of league teams and one for the defense of league teams. Before interleague play, these two were identical. I do not present both sets of totals (you can figure the defensive ones yourself from the team spreadsheet, if you desire), just those for the offenses. The exception is for the defense-specific statistics, like innings pitched and quality starts. The figures for those categories in the league report are for the defenses of the league's teams. However, I do include each league's breakdown of basic pitching stats between starters and relievers (denoted by "s" or "r" prefixes), and so summing those will yield the totals from the pitching side. The one abbreviation you might not recognize is "N"--this is the league average of runs/game for one team, and it will pop up again.
The Team spreadsheet focuses on overall team performance--wins, losses, runs scored, runs allowed. The columns included are: Park Factor (PF), Home Run Park Factor (PFhr), Winning Percentage (W%), Expected W% (EW%), Predicted W% (PW%), wins, losses, runs, runs allowed, Runs Created (RC), Runs Created Allowed (RCA), Home Winning Percentage (HW%), Road Winning Percentage (RW%) [exactly what they sound like--W% at home and on the road], Runs/Game (R/G), Runs Allowed/Game (RA/G), Runs Created/Game (RCG), Runs Created Allowed/Game (RCAG), and Runs Per Game (the average number of runs scored an allowed per game). Ideally, I would use outs as the denominator, but for teams, outs and games are so closely related that I don’t think it’s worth the extra effort.
The runs and Runs Created figures are unadjusted, but the per-game averages are park-adjusted, except for RPG which is also raw. Runs Created and Runs Created Allowed are both based on a simple Base Runs formula. The formula is:
A = H + W - HR - CS
B = (2TB - H - 4HR + .05W + 1.5SB)*.76
C = AB - H
D = HR
Naturally, A*B/(B + C) + D.
I have explained the methodology used to figure the PFs before, but the cliff’s notes version is that they are based on five years of data when applicable, include both runs scored and allowed, and they are regressed towards average (PF = 1), with the amount of regression varying based on the number of years of data used. There are factors for both runs and home runs. The initial PF (not shown) is:
iPF = (H*T/(R*(T - 1) + H) + 1)/2
where H = RPG in home games, R = RPG in road games, T = # teams in league (14 for AL and 16 for NL). Then the iPF is converted to the PF by taking x*iPF + (1-x), where x = .6 if one year of data is used, .7 for 2, .8 for 3, and .9 for 4+.
It is important to note, since there always seems to be confusion about this, that these park factors already incorporate the fact that the average player plays 50% on the road and 50% at home. That is what the adding one and dividing by 2 in the iPF is all about. So if I list Fenway Park with a 1.02 PF, that means that it actually increases RPG by 4%.
In the calculation of the PFs, I did not take out “home” games that were actually at neutral sites (of which there were a rash this year).
There are also Team Offense and Defense spreadsheets. These include the following categories:
Team offense: Plate Appearances, Batting Average (BA), On Base Average (OBA), Slugging Average (SLG), Secondary Average (SEC), Walks and Hit Batters per At Bat (WAB), Isolated Power (SLG - BA), R/G at home (hR/G), and R/G on the road (rR/G) BA, OBA, SLG, WAB, and ISO are park-adjusted by dividing by the square root of park factor (or the equivalent; WAB = (OBA - BA)/(1 - OBA), ISO = SLG - BA, and SEC = WAB + ISO).
Team defense: Innings Pitched, BA, OBA, SLG, Innings per Start (IP/S), Starter's eRA (seRA), Reliever's eRA (reRA), Quality Start Percentage (QS%), RA/G at home (hRA/G), RA/G on the road (rRA/G), Battery Mishap Rate (BMR), Modified Fielding Average (mFA), and Defensive Efficiency Record (DER). BA, OBA, and SLG are park-adjusted by dividing by the square root of PF; seRA and reRA are divided by PF.
The three fielding metrics I've included are limited it only to metrics that a) I can calculate myself and b) are based on the basic available data, not specialized PBP data. The three metrics are explained in this post, but here are quick descriptions of each:
1) BMR--wild pitches and passed balls per 100 baserunners = (WP + PB)/(H + W - HR)*100
2) mFA--fielding average removing strikeouts and assists = (PO - K)/(PO - K + E)
3) DER--the Bill James classic, using only the PA-based estimate of plays made. Based on a suggestion by Terpsfan101, I've tweaked the error coefficient. Plays Made = PA - K - H - W - HR - HB - .64E and DER = PM/(PM + H - HR + .64E)
Next are the individual player reports. I defined a starting pitcher as one with 15 or more starts. All other pitchers are eligible to be included as a reliever. If a pitcher has 40 appearances, then they are included. Additionally, if a pitcher has 50 innings and less than 50% of his appearances are starts, he is also included as a reliever (this allows some swingmen type pitchers who wouldn’t meet either the minimum start or appearance standards to get in). This would be a good point to note that I didn't do much to adjust for the opener--I made the decision to classify Ryan Yarbrough as a starter and Ryne Stanek as a reliever, but maybe next year I can implement some good ideas into the RAA/RAR methodology.
For all of the player reports, ages are based on simply subtracting their year of birth from 2017. I realize that this is not compatible with how ages are usually listed and so “Age 27” doesn’t necessarily correspond to age 27 as I list it, but it makes everything a heckuva lot easier, and I am more interested in comparing the ages of the players to their contemporaries than fitting them into historical studies, and for the former application it makes very little difference. The "R" category records rookie status with a "R" for rookies and a blank for everyone else; I've trusted Baseball Prospectus on this. Also, all players are counted as being on the team with whom they played/pitched (IP or PA as appropriate) the most.
For relievers, the categories listed are: Games, Innings Pitched, estimated Plate Appearances (PA), Run Average (RA), Relief Run Average (RRA), Earned Run Average (ERA), Estimated Run Average (eRA), DIPS Run Average (dRA), Strikeouts per Game (KG), Walks per Game (WG), Guess-Future (G-F), Inherited Runners per Game (IR/G), Batting Average on Balls in Play (%H), Runs Above Average (RAA), and Runs Above Replacement (RAR).
IR/G is per relief appearance (G - GS); it is an interesting thing to look at, I think, in lieu of actual leverage data. You can see which closers come in with runners on base, and which are used nearly exclusively to start innings. Of course, you can’t infer too much; there are bad relievers who come in with a lot of people on base, not because they are being used in high leverage situations, but because they are long men being used in low-leverage situations already out of hand.
For starting pitchers, the columns are: Wins, Losses, Innings Pitched, Estimated Plate Appearances (PA), RA, RRA, ERA, eRA, dRA, KG, WG, G-F, %H, Pitches/Start (P/S), Quality Start Percentage (QS%), RAA, and RAR. RA and ERA you know--R*9/IP or ER*9/IP, park-adjusted by dividing by PF. The formulas for eRA and dRA are based on the same Base Runs equation and they estimate RA, not ERA.
* eRA is based on the actual results allowed by the pitcher (hits, doubles, home runs, walks, strikeouts, etc.). It is park-adjusted by dividing by PF.
* dRA is the classic DIPS-style RA, assuming that the pitcher allows a league average %H, and that his hits in play have a league-average S/D/T split. It is park-adjusted by dividing by PF.
The formula for eRA is:
A = H + W - HR
B = (2*TB - H - 4*HR + .05*W)*.78
C = AB - H = K + (3*IP - K)*x (where x is figured as described below for PA estimation and is typically around .93) = PA (from below) - H - W
eRA = (A*B/(B + C) + HR)*9/IP
To figure dRA, you first need the estimate of PA described below. Then you calculate W, K, and HR per PA (call these %W, %K, and %HR). Percentage of balls in play (BIP%) = 1 - %W - %K - %HR. This is used to calculate the DIPS-friendly estimate of %H (H per PA) as e%H = Lg%H*BIP%.
Now everything has a common denominator of PA, so we can plug into Base Runs:
A = e%H + %W
B = (2*(z*e%H + 4*%HR) - e%H - 5*%HR + .05*%W)*.78
C = 1 - e%H - %W - %HR
cRA = (A*B/(B + C) + %HR)/C*a
z is the league average of total bases per non-HR hit (TB - 4*HR)/(H - HR), and a is the league average of (AB - H) per game.
In the past I presented a couple of batted ball RA estimates. I’ve removed these, not just because batted ball data exhibits questionable reliability but because these metrics were complicated to figure, required me to collate the batted ball data, and were not personally useful to me. I figure these stats for my own enjoyment and have in some form or another going back to 1997. I share them here only because I would do it anyway, so if I’m not interested in certain categories, there’s no reason to keep presenting them.
Instead, I’m showing strikeout and walk rate, both expressed as per game. By game I mean not nine innings but rather the league average of PA/G. I have always been a proponent of using PA and not IP as the denominator for non-run pitching rates, and now the use of per PA rates is widespread. Usually these are expressed as K/PA and W/PA, or equivalently, percentage of PA with a strikeout or walk. I don’t believe that any site publishes these as K and W per equivalent game as I am here. This is not better than K%--it’s simply applying a scalar multiplier. I like it because it generally follows the same scale as the familiar K/9.
To facilitate this, I’ve finally corrected a flaw in the formula I use to estimate plate appearances for pitchers. Previously, I’ve done it the lazy way by not splitting strikeouts out from other outs. I am now using this formula to estimate PA (where PA = AB + W):
PA = K + (3*IP - K)*x + H + W
Where x = league average of (AB - H - K)/(3*IP - K)
Then KG = K*Lg(PA/G) and WG = W*Lg(PA/G).
G-F is a junk stat, included here out of habit because I've been including it for years. It was intended to give a quick read of a pitcher's expected performance in the next season, based on eRA and strikeout rate. Although the numbers vaguely resemble RAs, it's actually unitless. As a rule of thumb, anything under four is pretty good for a starter. G-F = 4.46 + .095(eRA) - .113(K*9/IP). It is a junk stat. JUNK STAT JUNK STAT JUNK STAT. Got it?
%H is BABIP, more or less--%H = (H - HR)/(PA - HR - K - W), where PA was estimated above. Pitches/Start includes all appearances, so I've counted relief appearances as one-half of a start (P/S = Pitches/(.5*G + .5*GS). QS% is just QS/(G - GS); I don't think it's particularly useful, but Doug's Stats include QS so I include it.
I've used a stat called Relief Run Average (RRA) in the past, based on Sky Andrecheck's article in the August 1999 By the Numbers; that one only used inherited runners, but I've revised it to include bequeathed runners as well, making it equally applicable to starters and relievers. I use RRA as the building block for baselined value estimates for all pitchers. I explained RRA in this article, but the bottom line formulas are:
BRSV = BRS - BR*i*sqrt(PF)
IRSV = IR*i*sqrt(PF) - IRS
RRA = ((R - (BRSV + IRSV))*9/IP)/PF
The two baselined stats are Runs Above Average (RAA) and Runs Above Replacement (RAR). Starting in 2015 I revised RAA to use a slightly different baseline for starters and relievers as described here. The adjustment is based on patterns from the last several seasons of league average starter and reliever eRA. Thus it does not adjust for any advantages relief pitchers enjoy that are not reflected in their component statistics. This could include runs allowed scoring rules that benefit relievers (although the use of RRA should help even the scales in this regard, at least compared to raw RA) and the talent advantage of starting pitchers. The RAR baselines do attempt to take the latter into account, and so the difference in starter and reliever RAR will be more stark than the difference in RAA.
RAA (relievers) = (.951*LgRA - RRA)*IP/9
RAA (starters) = (1.025*LgRA - RRA)*IP/9
RAR (relievers) = (1.11*LgRA - RRA)*IP/9
RAR (starters) = (1.28*LgRA - RRA)*IP/9
All players with 250 or more plate appearances (official, total plate appearances) are included in the Hitters spreadsheets (along with some players close to the cutoff point who I was interested in). Each is assigned one position, the one at which they appeared in the most games. The statistics presented are: Games played (G), Plate Appearances (PA), Outs (O), Batting Average (BA), On Base Average (OBA), Slugging Average (SLG), Secondary Average (SEC), Runs Created (RC), Runs Created per Game (RG), Speed Score (SS), Hitting Runs Above Average (HRAA), Runs Above Average (RAA), Hitting Runs Above Replacement (HRAR), and Runs Above Replacement (RAR).
Starting in 2015, I'm including hit batters in all related categories for hitters, so PA is now equal to AB + W+ HB. Outs are AB - H + CS. BA and SLG you know, but remember that without SF, OBA is just (H + W + HB)/(AB + W + HB). Secondary Average = (TB - H + W + HB)/AB = SLG - BA + (OBA - BA)/(1 - OBA). I have not included net steals as many people (and Bill James himself) do, but I have included HB which some do not.
BA, OBA, and SLG are park-adjusted by dividing by the square root of PF. This is an approximation, of course, but I'm satisfied that it works well (I plan to post a couple articles on this some time during the offseason). The goal here is to adjust for the win value of offensive events, not to quantify the exact park effect on the given rate. I use the BA/OBA/SLG-based formula to figure SEC, so it is park-adjusted as well.
Runs Created is actually Paul Johnson's ERP, more or less. Ideally, I would use a custom linear weights formula for the given league, but ERP is just so darn simple and close to the mark that it’s hard to pass up. I still use the term “RC” partially as a homage to Bill James (seriously, I really like and respect him even if I’ve said negative things about RC and Win Shares), and also because it is just a good term. I like the thought put in your head when you hear “creating” a run better than “producing”, “manufacturing”, “generating”, etc. to say nothing of names like “equivalent” or “extrapolated” runs. None of that is said to put down the creators of those methods--there just aren’t a lot of good, unique names available.
For 2015, I refined the formula a little bit to:
1. include hit batters at a value equal to that of a walk
2. value intentional walks at just half the value of a regular walk
3. recalibrate the multiplier based on the last ten major league seasons (2005-2014)
This revised RC = (TB + .8H + W + HB - .5IW + .7SB - CS - .3AB)*.310
RC is park adjusted by dividing by PF, making all of the value stats that follow park adjusted as well. RG, the Runs Created per Game rate, is RC/O*25.5. I do not believe that outs are the proper denominator for an individual rate stat, but I also do not believe that the distortions caused are that bad. (I still intend to finish my rate stat series and discuss all of the options in excruciating detail, but alas you’ll have to take my word for it now).
Several years ago I switched from using my own "Speed Unit" to a version of Bill James' Speed Score; of course, Speed Unit was inspired by Speed Score. I only use four of James' categories in figuring Speed Score. I actually like the construct of Speed Unit better as it was based on z-scores in the various categories (and amazingly a couple other sabermetricians did as well), but trying to keep the estimates of standard deviation for each of the categories appropriate was more trouble than it was worth.
Speed Score is the average of four components, which I'll call a, b, c, and d:
a = ((SB + 3)/(SB + CS + 7) - .4)*20
b = sqrt((SB + CS)/(S + W))*14.3
c = ((R - HR)/(H + W - HR) - .1)*25
d = T/(AB - HR - K)*450
James actually uses a sliding scale for the triples component, but it strikes me as needlessly complex and so I've streamlined it. He looks at two years of data, which makes sense for a gauge that is attempting to capture talent and not performance, but using multiple years of data would be contradictory to the guiding principles behind this set of reports (namely, simplicity. Or laziness. You're pick.) I also changed some of his division to mathematically equivalent multiplications.
There are a whopping four categories that compare to a baseline; two for average, two for replacement. Hitting RAA compares to a league average hitter; it is in the vein of Pete Palmer’s Batting Runs. RAA compares to an average hitter at the player’s primary position. Hitting RAR compares to a “replacement level” hitter; RAR compares to a replacement level hitter at the player’s primary position. The formulas are:
HRAA = (RG - N)*O/25.5
RAA = (RG - N*PADJ)*O/25.5
HRAR = (RG - .73*N)*O/25.5
RAR = (RG - .73*N*PADJ)*O/25.5
PADJ is the position adjustment, and it is based on 2002-2011 offensive data. For catchers it is .89; for 1B/DH, 1.17; for 2B, .97; for 3B, 1.03; for SS, .93; for LF/RF, 1.13; and for CF, 1.02. I had been using the 1992-2001 data as a basis for some time, but finally updated for 2012. I’m a little hesitant about this update, as the middle infield positions are the biggest movers (higher positional adjustments, meaning less positional credit). I have no qualms for second base, but the shortstop PADJ is out of line with the other position adjustments widely in use and feels a bit high to me. But there are some decent points to be made in favor of offensive adjustments, and I’ll have a bit more on this topic in general below.
That was the mechanics of the calculations; now I'll twist myself into knots trying to justify them. If you only care about the how and not the why, stop reading now.
The first thing that should be covered is the philosophical position behind the statistics posted here. They fall on the continuum of ability and value in what I have called "performance". Performance is a technical-sounding way of saying "Whatever arbitrary combination of ability and value I prefer".
With respect to park adjustments, I am not interested in how any particular player is affected, so there is no separate adjustment for lefties and righties for instance. The park factor is an attempt to determine how the park affects run scoring rates, and thus the win value of runs.
I apply the park factor directly to the player's statistics, but it could also be applied to the league context. The advantage to doing it my way is that it allows you to compare the component statistics (like Runs Created or OBA) on a park-adjusted basis. The drawback is that it creates a new theoretical universe, one in which all parks are equal, rather than leaving the player grounded in the actual context in which he played and evaluating how that context (and not the player's statistics) was altered by the park.
The good news is that the two approaches are essentially equivalent; in fact, they are precisely equivalent if you assume that the Runs Per Win factor is equal to the RPG. Suppose that we have a player in an extreme park (PF = 1.15, approximately like Coors Field pre-humidor) who has an 8 RG before adjusting for park, while making 350 outs in a 4.5 N league. The first method of park adjustment, the one I use, converts his value into a neutral park, so his RG is now 8/1.15 = 6.957. We can now compare him directly to the league average:
RAA = (6.957 - 4.5)*350/25.5 = +33.72
The second method would be to adjust the league context. If N = 4.5, then the average player in this park will create 4.5*1.15 = 5.175 runs. Now, to figure RAA, we can use the unadjusted RG of 8:
RAA = (8 - 5.175)*350/25.5 = +38.77
These are not the same, as you can obviously see. The reason for this is that they take place in two different contexts. The first figure is in a 9 RPG (2*4.5) context; the second figure is in a 10.35 RPG (2*4.5*1.15) context. Runs have different values in different contexts; that is why we have RPW converters in the first place. If we convert to WAA (using RPW = RPG, which is only an approximation, so it's usually not as tidy as it appears below), then we have:
WAA = 33.72/9 = +3.75
WAA = 38.77/10.35 = +3.75
Once you convert to wins, the two approaches are equivalent. The other nice thing about the first approach is that once you park-adjust, everyone in the league is in the same context, and you can dispense with the need for converting to wins at all. You still might want to convert to wins, and you'll need to do so if you are comparing the 2015 players to players from other league-seasons (including between the AL and NL in the same year), but if you are only looking to compare Christian Yelich to Matt Carpenter, it's not necessary. WAR is somewhat ubiquitous now, but personally I prefer runs when possible--why mess with decimal points if you don't have to?
The park factors used to adjust player stats here are run-based. Thus, they make no effort to project what a player "would have done" in a neutral park, or account for the difference effects parks have on specific events (walks, home runs, BA) or types of players. They simply account for the difference in run environment that is caused by the park (as best I can measure it). As such, they don't evaluate a player within the actual run context of his team's games; they attempt to restate the player's performance as an equivalent performance in a neutral park.
I suppose I should also justify the use of sqrt(PF) for adjusting component statistics. The classic defense given for this approach relies on basic Runs Created--runs are proportional to OBA*SLG, and OBA*SLG/PF = OBA/sqrt(PF)*SLG/sqrt(PF). While RC may be an antiquated tool, you will find that the square root adjustment is fairly compatible with linear weights or Base Runs as well. I am not going to take the space to demonstrate this claim here, but I will some time in the future.
Many value figures published around the sabersphere adjust for the difference in quality level between the AL and NL. I don't, but this is a thorny area where there is no right or wrong answer as far as I'm concerned. I also do not make an adjustment in the league averages for the fact that the overall NL averages include pitcher batting and the AL does not (not quite true in the era of interleague play, but you get my drift).
The difference between the leagues may not be precisely calculable, and it certainly is not constant, but it is real. If the average player in the AL is better than the average player in the NL, it is perfectly reasonable to expect the average AL player to have more RAR than the average NL player, and that will not happen without some type of adjustment. On the other hand, if you are only interested in evaluating a player relative to his own league, such an adjustment is not necessarily welcome.
The league argument only applies cleanly to metrics baselined to average. Since replacement level compares the given player to a theoretical player that can be acquired on the cheap, the same pool of potential replacement players should by definition be available to the teams of each league. One could argue that if the two leagues don't have equal talent at the major league level, they might not have equal access to replacement level talent--except such an argument is at odds with the notion that replacement level represents talent that is truly "freely available".
So it's hard to justify the approach I take, which is to set replacement level relative to the average runs scored in each league, with no adjustment for the difference in the leagues. The best justification is that it's simple and it treats each league as its own universe, even if in reality they are connected.
The replacement levels I have used here are very much in line with the values used by other sabermetricians. This is based both on my own "research", my interpretation of other's people research, and a desire to not stray from consensus and make the values unhelpful to the majority of people who may encounter them.
Replacement level is certainly not settled science. There is always going to be room to disagree on what the baseline should be. Even if you agree it should be "replacement level", any estimate of where it should be set is just that--an estimate. Average is clean and fairly straightforward, even if its utility is questionable; replacement level is inherently messy. So I offer the average baseline as well.
For position players, replacement level is set at 73% of the positional average RG (since there's a history of discussing replacement level in terms of winning percentages, this is roughly equivalent to .350). For starting pitchers, it is set at 128% of the league average RA (.380), and for relievers it is set at 111% (.450).
I am still using an analytical structure that makes the comparison to replacement level for a position player by applying it to his hitting statistics. This is the approach taken by Keith Woolner in VORP (and some other earlier replacement level implementations), but the newer metrics (among them Rally and Fangraphs' WAR) handle replacement level by subtracting a set number of runs from the player's total runs above average in a number of different areas (batting, fielding, baserunning, positional value, etc.), which for lack of a better term I will call the subtraction approach.
The offensive positional adjustment makes the inherent assumption that the average player at each position is equally valuable. I think that this is close to being true, but it is not quite true. The ideal approach would be to use a defensive positional adjustment, since the real difference between a first baseman and a shortstop is their defensive value. When you bat, all runs count the same, whether you create them as a first baseman or as a shortstop.
That being said, using "replacement hitter at position" does not cause too many distortions. It is not theoretically correct, but it is practically powerful. For one thing, most players, even those at key defensive positions, are chosen first and foremost for their offense. Empirical research by Keith Woolner has shown that the replacement level hitting performance is about the same for every position, relative to the positional average.
Figuring what the defensive positional adjustment should be, though, is easier said than done. Therefore, I use the offensive positional adjustment. So if you want to criticize that choice, or criticize the numbers that result, be my guest. But do not claim that I am holding this up as the correct analytical structure. I am holding it up as the most simple and straightforward structure that conforms to reality reasonably well, and because while the numbers may be flawed, they are at least based on an objective formula that I can figure myself. If you feel comfortable with some other assumptions, please feel free to ignore mine.
That still does not justify the use of HRAR--hitting runs above replacement--which compares each hitter, regardless of position, to 73% of the league average. Basically, this is just a way to give an overall measure of offensive production without regard for position with a low baseline. It doesn't have any real baseball meaning.
A player who creates runs at 90% of the league average could be above-average (if he's a shortstop or catcher, or a great fielder at a less important fielding position), or sub-replacement level (DHs that create 3.5 runs per game are not valuable properties). Every player is chosen because his total value, both hitting and fielding, is sufficient to justify his inclusion on the team. HRAR fails even if you try to justify it with a thought experiment about a world in which defense doesn't matter, because in that case the absolute replacement level (in terms of RG, without accounting for the league average) would be much higher than it is currently.
The specific positional adjustments I use are based on 2002-2011 data. I stick with them because I have not seen compelling evidence of a change in the degree of difficulty or scarcity between the positions between now and then, and because I think they are fairly reasonable. The positions for which they diverge the most from the defensive position adjustments in common use are 2B, 3B, and CF. Second base is considered a premium position by the offensive PADJ (.97), while third base and center field have similar adjustments in the opposite direction (1.03 and 1.02).
Another flaw is that the PADJ is applied to the overall league average RG, which is artificially low for the NL because of pitcher's batting. When using the actual league average runs/game, it's tough to just remove pitchers--any adjustment would be an estimate. If you use the league total of runs created instead, it is a much easier fix.
One other note on this topic is that since the offensive PADJ is a stand-in for average defensive value by position, ideally it would be applied by tying it to defensive playing time. I have done it by outs, though.
The reason I have taken this flawed path is because 1) it ties the position adjustment directly into the RAR formula rather than leaving it as something to subtract on the outside and more importantly 2) there’s no straightforward way to do it. The best would be to use defensive innings--set the full-time player to X defensive innings, figure how Derek Jeter’s innings compared to X, and adjust his PADJ accordingly. Games in the field or games played are dicey because they can cause distortion for defensive replacements. Plate Appearances avoid the problem that outs have of being highly related to player quality, but they still carry the illogic of basing it on offensive playing time. And of course the differences here are going to be fairly small (a few runs). That is not to say that this way is preferable, but it’s not horrible either, at least as far as I can tell.
To compare this approach to the subtraction approach, start by assuming that a replacement level shortstop would create .86*.73*4.5 = 2.825 RG (or would perform at an overall level of equivalent value to being an average fielder at shortstop while creating 2.825 runs per game). Suppose that we are comparing two shortstops, each of whom compiled 600 PA and played an equal number of defensive games and innings (and thus would have the same positional adjustment using the subtraction approach). Alpha made 380 outs and Bravo made 410 outs, and each ranked as dead-on average in the field.
The difference in overall RAR between the two using the subtraction approach would be equal to the difference between their offensive RAA compared to the league average. Assuming the league average is 4.5 runs, and that both Alpha and Bravo created 75 runs, their offensive RAAs are:
Alpha = (75*25.5/380 - 4.5)*380/25.5 = +7.94
Similarly, Bravo is at +2.65, and so the difference between them will be 5.29 RAR.
Using the flawed approach, Alpha's RAR will be:
(75*25.5/380 - 4.5*.73*.86)*380/25.5 = +32.90
Bravo's RAR will be +29.58, a difference of 3.32 RAR, which is two runs off of the difference using the subtraction approach.
The downside to using PA is that you really need to consider park effects if you do, whereas outs allow you to sidestep park effects. Outs are constant; plate appearances are linked to OBA. Thus, they not only depend on the offensive context (including park factor), but also on the quality of one's team. Of course, attempting to adjust for team PA differences opens a huge can of worms which is not really relevant; for now, the point is that using outs for individual players causes distortions, sometimes trivial and sometimes bothersome, but almost always makes one's life easier.
I do not include fielding (or baserunning outside of steals, although that is a trivial consideration in comparison) in the RAR figures--they cover offense and positional value only). This in no way means that I do not believe that fielding is an important consideration in player evaluation. However, two of the key principles of these stat reports are 1) not incorporating any data that is not readily available and 2) not simply including other people's results (of course I borrow heavily from other people's methods, but only adapting methodology that I can apply myself).
Any fielding metric worth its salt will fail to meet either criterion--they use zone data or play-by-play data which I do not have easy access to. I do not have a fielding metric that I have stapled together myself, and so I would have to simply lift other analysts' figures.
Setting the practical reason for not including fielding aside, I do have some reservations about lumping fielding and hitting value together in one number because of the obvious differences in reliability between offensive and fielding metrics. In theory, they absolutely should be put together. But in practice, I believe it would be better to regress the fielding metric to a point at which it would be roughly equivalent in reliability to the offensive metric.
Offensive metrics have error bars associated with them, too, of course, and in evaluating a single season's value, I don't care about the vagaries that we often lump together as "luck". Still, there are errors in our assessment of linear weight values and players that collect an unusual proportion of infield hits or hits to the left side, errors in estimation of park factor, and any number of other factors that make their events more or less valuable than an average event of that type.
Fielding metrics offer up all of that and more, as we cannot be nearly as certain of true successes and failures as we are when analyzing offense. Recent investigations, particularly by Colin Wyers, have raised even more questions about the level of uncertainty. So, even if I was including a fielding value, my approach would be to assume that the offensive value was 100% reliable (which it isn't), and regress the fielding metric relative to that (so if the offensive metric was actually 70% reliable, and the fielding metric 40% reliable, I'd treat the fielding metric as .4/.7 = 57% reliable when tacking it on, to illustrate with a simplified and completely made up example presuming that one could have a precise estimate of nebulous "reliability").
Given the inherent assumption of the offensive PADJ that all positions are equally valuable, once RAR has been figured for a player, fielding value can be accounted for by adding on his runs above average relative to a player at his own position. If there is a shortstop that is -2 runs defensively versus an average shortstop, he is without a doubt a plus defensive player, and a more valuable defensive player than a first baseman who was +1 run better than an average first baseman. Regardless, since it was implicitly assumed that they are both average defensively for their position when RAR was calculated, the shortstop will see his value docked two runs. This DOES NOT MEAN that the shortstop has been penalized for his defense. The whole process of accounting for positional differences, going from hitting RAR to positional RAR, has benefited him.
I've found that there is often confusion about the treatment of first baseman and designated hitters in my PADJ methodology, since I consider DHs as in the same pool as first baseman. The fact of the matter is that first baseman outhit DH. There are any number of potential explanations for this; DHs are often old or injured, players hit worse when DHing than they do when playing the field, etc. This actually helps first baseman, since the DHs drag the average production of the pool down, thus resulting in a lower replacement level than I would get if I considered first baseman alone.
However, this method does assume that a 1B and a DH have equal defensive value. Obviously, a DH has no defensive value. What I advocate to correct this is to treat a DH as a bad defensive first baseman, and thus knock another five or so runs off of his RAR for a full-time player. I do not incorporate this into the published numbers, but you should keep it in mind. However, there is no need to adjust the figures for first baseman upwards --the only necessary adjustment is to take the DHs down a notch.
Finally, I consider each player at his primary defensive position (defined as where he appears in the most games), and do not weight the PADJ by playing time. This does shortchange a player like Ben Zobrist (who saw significant time at a tougher position than his primary position), and unduly boost a player like Buster Posey (who logged a lot of games at a much easier position than his primary position). For most players, though, it doesn't matter much. I find it preferable to make manual adjustments for the unusual cases rather than add another layer of complexity to the whole endeavor.
2018 League
2018 Park Factors
2018 Team
2018 Team Defense
2018 Team Offense
2018 AL Relievers
2018 NL Relievers
2018 AL Starters
2018 NL Starters
2018 AL Hitters
2018 NL Hitters
Monday, October 01, 2018
Crude Playoff Odds -- 2018
These are very simple playoff odds, based on my crude rating system for teams using an equal mix of W%, EW% (based on R/RA), PW% (based on RC/RCA), and 69 games of .500. They account for home field advantage by assuming a .500 team wins 54.2% of home games (major league average 2006-2015). They assume that a team's inherent strength is constant from game-to-game. They do not generally account for any number of factors that you would actually want to account for if you were serious about this, including but not limited to injuries, the current construction of the team rather than the aggregate seasonal performance, pitching rotations, estimated true talent of the players, etc.
The CTRs that are fed in are:

Wilcard game odds (the least useful since the pitching matchups aren’t taken into account, and that matters most when there is just one game):

LDS:

LCS:

WS:

Because I set this spreadsheet up when home field advantage went to a particular league (as it has been for the entire history of the World Series prior to this year), all of the AL teams are listed as the home team. But the probabilities all consider which team would actually have the home field advantage in each matchup. Incidentally, the first tiebreaker after overall record is intra-divisional record, which if anything should favor the team with the worse record but would amusingly give Cleveland home field advantage in a series against Los Angeles or Colorado.
Putting it all together:
