Every year I state that by the time this post rolls around next year, I hope to have a fully functional Enby distribution to allow the metrics herein to be more flexible (e.g. not based solely on empirical data, able to handle park effects, etc.) And every year during the year I fail to do so. “Wait ‘til next year”...the Indians taking over the longest World Series title drought in spectacular fashion has now given me an excuse to apply this to any baseball-related shortcoming on my part. This time, it really should be next year; what kept me from finishing up over the last twelve months was only partly distraction but largely perfectionism on a minor portion of the Enby methodology that I think I now have convinced myself is folly.
Anyway, there are some elements of Enby in this post, as I’ve written enough about the model to feel comfortable using bits and pieces. But I’d like to overhaul the calculation of gOW% and gDW% that are used at the end based on Enby, and I’m not ready to do that just yet given the deficiency of the material I’ve published on Enby.
Self-indulgence, aggrandizement, and deprecation aside, I need to caveat that this post in no way accounts for park effects. But that won’t come in to play as I first look at team record in blowouts and non-blowouts, with a blowout defined as 5+ runs. Obviously some five run games are not truly blowouts, and some are; one could probably use WPA to make a better definition of blowout based on some sort of average win probability, or the win probability at a given moment or moments in the game. I should also note that Baseball-Reference uses this same definition of blowout. I am not sure when they started publishing it; they may well have pre-dated by usage of five runs as the delineator. However, I did not adopt that as my standard because of Baseball-Reference, I adopted it because it made the most sense to me being unaware of any B-R standard.
73.0% of major league games in 2015 were non-blowouts (of course 27.0% were). The leading records in non-blowouts:

Texas was much the best in close-ish games; their extraordinary record in one-run games which of course are a subset of non-blowouts was well documented. The Blue Jays have made it to consecutive ALCS, but their non-blowout regular season record in 2015-16 is just 116-115. Also, if you audit this you may note that the total comes to 1771-1773, which is obviously wrong. I used Baseball Prospectus' data.
Records in blowouts:

It should be no surprise that the Cubs were the best in blowouts. Toronto was nearly as good last year, 37-12, for a two-year blowout record of 66-27 (.710).
The largest differences (blowout - non-blowout W%) and percentage of blowouts and non-blowouts for each team:

It is rare to see a playoff team with such a large negative differential as Texas had. Colorado played the highest percentage of blowouts and San Diego the lowest, which shouldn’t come as a surprise given that scoring environment has a large influence. Outside of Colorado, though, the Cubs and the Indians played the highest percentage of blowout games, with the latter not sporting as a high of a W% but having the second most blowout wins.
A more interesting way to consider game-level results is to look at how teams perform when scoring or allowing a given number of runs. For the majors as a whole, here are the counts of games in which teams scored X runs:

The “marg” column shows the marginal W% for each additional run scored. In 2015, the third run was both the run with the greatest marginal impact on the chance of winning, while it took a fifth run to make a team more likely to win than lose. 2016 was the first time since 2008 that teams scoring four runs had a losing record, a product of the resurgence in run scoring levels.
I use these figures to calculate a measure I call game Offensive W% (or Defensive W% as the case may be), which was suggested by Bill James in an old Abstract. It is a crude way to use each team’s actual runs per game distribution to estimate what their W% should have been by using the overall empirical W% by runs scored for the majors in the particular season.
The theoretical distribution from Enby discussed earlier would be much preferable to the empirical distribution for this exercise, but I’ve defaulted to the 2016 empirical data. Some of the drawbacks of this approach are:
1. The empirical distribution is subject to sample size fluctuations. In 2016, all 58 times that a team scored twelve runs in a game, they won; meanwhile, teams that scored thirteen runs were 46-1. Does that mean that scoring 12 runs is preferable to scoring 13 runs? Of course not--it's a quirk in the data. Additionally, the marginal values don’t necessary make sense even when W% increases from one runs scored level to another (In figuring the gEW% family of measures below, I lumped games with 12+ runs together, which smoothes any illogical jumps in the win function, but leaves the inconsistent marginal values unaddressed and fails to make any differentiation between scoring in that range. The values actually used are displayed in the “use” column, and the invuse” column is the complements of these figures--i.e. those used to credit wins to the defense.)
2. Using the empirical distribution forces one to use integer values for runs scored per game. Obviously the number of runs a team scores in a game is restricted to integer values, but not allowing theoretical fractional runs makes it very difficult to apply any sort of park adjustment to the team frequency of runs scored.
3. Related to #2 (really its root cause, although the park issue is important enough from the standpoint of using the results to evaluate teams that I wanted to single it out), when using the empirical data there is always a tradeoff that must be made between increasing the sample size and losing context. One could use multiple years of data to generate a smoother curve of marginal win probabilities, but in doing so one would lose centering at the season’s actual run scoring rate. On the other hand, one could split the data into AL and NL and more closely match context, but you would lose sample size and introduce more quirks into the data.
I keep promising that I will use Enby to replace the empirical approach, but for now I will use Enby for a couple graphs but nothing more.
First, a comparison of the actual distribution of runs per game in the majors to that predicted by the Enby distribution for the 2016 major league average of 4.479 runs per game (Enby distribution parameters are B = 1.1052, r = 4.082, z = .0545):

This is pretty typical of the kind of fit you will see from Enby for a given season: a few important points where there’s a noticeable difference (in this case even tallies two, four, six on the high side and 1 and 7 on the low side), but generally acquitting itself as a decent model of the run distribution.
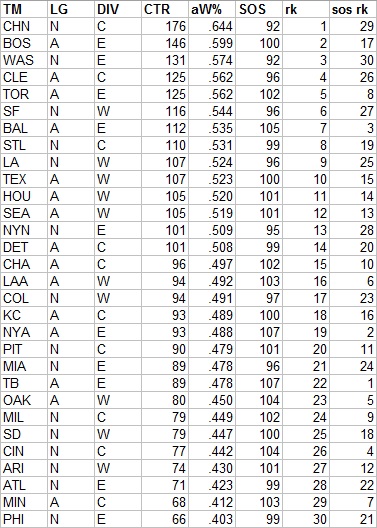
I will not go into the full details of how gOW%, gDW%, and gEW% (which combines both into one measure of team quality) are calculated in this post, but full details were provided here and the paragraph below gives a quick explanation. The “use” column here is the coefficient applied to each game to calculate gOW% while the “invuse” is the coefficient used for gDW%. For comparison, I have looked at OW%, DW%, and EW% (Pythagenpat record) for each team; none of these have been adjusted for park to maintain consistency with the g-family of measures which are not park-adjusted.
A team’s gOW% is the sumproduct of their frequency of scoring x runs, where x runs from 0 to 22, and the empirical W% of teams in 2015 when they scored x runs. For example, Philadelphia was shutout 11 times; they would not be expected to win any of those games (nor would they, we can be certain). They scored one run 23 times; an average team in 2016 had a .089 W% when scoring one run, so they could have been expected to win 2.04of the 23 games given average defense. They scored two runs 22 times; an average team had a .228 W% when scoring two, so they could have been expected to win 5.02 of those games given average defense. Sum up the estimated wins for each value of x and divide by the team’s total number of games and you have gOW%.
It is thus an estimate of what W% a team with the given team’s empirical distribution of runs scored and a league average defense would have. It is analogous to James’ original construct of OW% except looking at the empirical distribution of runs scored rather than the average runs scored per game. (To avoid any confusion, James in 1986 also proposed constructing an OW% in the manner in which I calculate gOW%).
For most teams, gOW% and OW% are very similar. Teams whose gOW% is higher than OW% distributed their runs more efficiently (at least to the extent that the methodology captures reality); the reverse is true for teams with gOW% lower than OW%. The teams that had differences of +/- 2 wins between the two metrics were (all of these are the g-type less the regular estimate):
Positive: MIA, PHI, ATL, KC
Negative: LA, SEA
The Marlins offense had the largest difference (3.55) between their corresponding g-type W% and their OW%/DW%, so I like to include a run distribution chart to hopefully ease in understanding what this means. Miami scored 4.167 R/G, so their Enby parameters (r = 3.923, B = 1.0706, z = .0649) produce these estimated frequencies:

Miami scored 0-3 runs in 47.8% of their games compared to an expected 47.9%. But by scoring 0-2 runs 3% less often then expected and scoring three 3% more often, they had 1.3 more expected wins from such games than Enby expected. They added an additional 1.2 wins from 4-6 runs, and lost 1.1 from 7+ runs. (Note that the total doesn’t add up to the difference between their gOW% and OW%, nor should it--the comparisons I was making were between what the empirical 2016 major league W%s for each x runs scored predicted using their actual run distribution and their Enby run distribution. If I had my act together and was using Enby to estimate the expected W% at each x runs scored, then we would expect a comparison like the preceding to be fairly consistent with a comparison of gOW% to OW%).
Teams with differences of +/- 2 wins between gDW% and standard DW%:
Positive: CIN, COL, ARI
Negative: NYN, MIL, MIA, TB, NYA
The Marlins were the only team to appear on both the offense and defense list, their defense giving back 2.75 wins when looking at their run distribution rather than run average.
Teams with differences of +/- 2 wins between gEW% and standard EW%:
Positive: PHI, TEX, CIN, KC
Negative: LA, SEA, NYN, MIL, NYA, BOS
The Royals finally showed up on these lists, but turning a .475 EW% into a .488 gEW% is not enough pixie dust to make the playoffs.
Below is a full chart with the various actual and estimated W%s: